Elasticsearch 알아보기 - 1편
Elasticsearch(엘라스틱서치)란?
Apache Lucene( 아파치 루씬 ) 기반의 검색 & 분석 엔진으로 방대한 양의 데이터를 빠르게 저장,검색,분석할 수 있다.
ELK(Elasticsearch / Logstash / Kibana) 조합으로 많이 사용 됨.
- Logstash : 다양한 데이터를 수집, 가공하여 Elasticsearch로 전달
-
Elasticsearch: Logstash로부터 받은 데이터를 저장하고 클라이언트에서 요청한 검색 및 분석을 수행.
- Kibana: Elasticsearch 데이터를 시각화 및 모니터링
- Beats: 경량 데이터 수집기로 Logstash나 Elasticsearch에 데이터를 전송.
- Beats 개발 이유: https://esbook.kimjmin.net/01-overview/1.1-elastic-stack/1.1.4-beats
Elasticsearch가 대용량 데이터를 빠르게 검색할 수 있는 이유는 역인덱스(Inverted file index) 데이터 구조를 사용하여 Full text 검색이 가능한 구조로 되어 있기 때문인데, 역인덱스는 서적 맨 뒷편에 색인된 키워드를 이용해 역으로 본문을 찾는 방식이다.
Elasicserach의 핵심 기능들은 Apache 2.0 라이센스로 배포되고 있으며, 6.3 버전부터는 Elastic 라이센스와 Apache 라이센스가 섞여있다.
Elastic사에서 AWS를 막기 위해 라이센스를 변경했고, AWS는 Apache 2.0 라이센스의 Elasticsearch를 fork하여 직접 운영하겠다고 발표한 이슈가 있다.
Elasticsearch 장단점
장점
-
RDB보다 빠른 검색/저장이 가능하고 Simple한 데이터 구조
- Replica를 통해 고가용성을 확보할 수 있다.
- 샤드를 통해 Scale out이 용이하고, Node 확장이 쉽다.
- 데이터 작업을 CRUD Rest API를 통해 수행할 수 있기 때문에 http를 사용할 수 있는 모든 플랫폼에서 사용할 수 있다.
단점
- RDB와 다르게 실시간 처리는 되지 않는다. 인메모리 버퍼 -> 시스템 캐시 -> 디스크 순으로 저장되는데 시스템 캐시까지 저장되어야 검색이 가능해진다.
- update 기능이 없고, 기존 데이터를 Soft-Delete(delete flag=true)하고 새로운 데이터 생성한다.
- 커밋이나 롤백 등의 트랜잭션 개념이 없다.
Elasticsearch 용어
-
색인(indexing): 데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들로 변환하여 저장하는 과정.
-
index : datbase, 색인된 데이터 집합
-
shard: physical partition
-
type: table , Elasticsearch 7.0 이상 부터는 하나의 index에 하나의 type만 가질 수 있다.
-
document: row
-
field : column
-
mapping : schema
-
Query DSL : SQL
Elasticsearch Cluster
최소 하나 이상의 노드로 이루어진 Elasticsearch 노드의 집합.
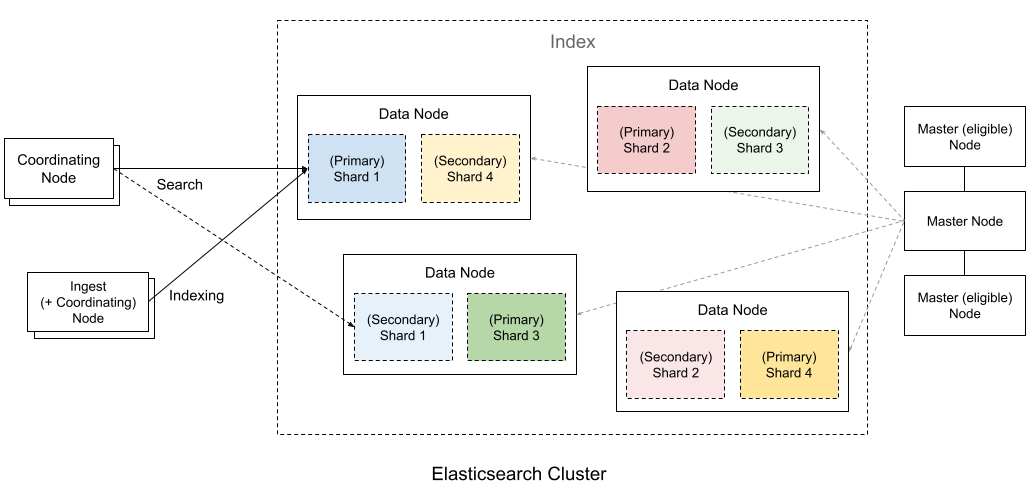
노드는 클러스터에 포함된 단일 서버로 데이터를 저장하고 색인 및 검색을 수행하며 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있다.
- Master-eligible Node: 클러스터를 제어하는 마스터 노드이며, 노드, 인덱스, 샤드 등을 관리 한다.
- Data Node: 데이터가 저장되는 노드이며, 색인, 검색, 통계 등 데이터 작업을 수행하기 때문에 많은 시스템 리소스가 필요로 한다.
- Ingest Node: 데이터를 변환하는 등의 사전 처리 파이라인을 실행하는 역할을 한다.
- Coordination only node: 로드 밸런싱 역할하는 수행하는 노드이며, aggregation(집합) 쿼리 요청을 각 data node에 적절하게 요청을 분산하고 이를 취합하는 역할을 한다. 이 노드를 설정하지 않는다면 하나의 노드에서 aggregation 쿼리를 수행하게 되기 때문에 많은 리소스를 사용하게 된다.
보통 하나의 서버에 하나의 노드를 실행하는 것을 권장한다.
기본적으로 Master node와 Data node를 두고, 규모에 따라 Ingest Node, Coordnation only node를 같이 사용하면 될 것 같다.
Cluster를 구성할 때 HA를 위해 master node는 최소 3대이상의 홀수로 구성하면 좋다.
Master node를 한 대로 구성할 경우 Master node에 장애가 발생하면 Elasticsearch를 이용하는 서비스 모두 장애가 발생할 수 있다.
Master node를 두 대로 구성할 경우 정합성 문제가 발생할 수 있다. 두 개 마스터 노드간 네트워크가 단절될 경우 각 마스터 노드가 별도로 동작하게 되고, 다시 네트워크가 원복되어 하나의 클러스터로 합쳐질 경우 두 마스터 노드간 데이터 정합성 문제가 발생할 수 있는데 이를 Split Brain이라고 한다. 그래서 마스터 후보 노드를 3개를 두고 2개 이상 마스터 노드가 동작하지 않을 경우 클러스터 동작을 멈추도록 설정해야 한다.
7.0 부터는 discovery.zen.minimum_master_nodes 설정이 사라지고 대신 node.master: true 인 노드가 추가되면 클러스터가 스스로 minimum_master_nodes 노드 값을 변경되었으며, 사용자는 최초 마스터 후보로 선출할 cluster.initial_master_nodes: [ ] 값만 설정하면 된다.
인덱스와 샤드
인덱스를 생성할 때 별도의 설정을 하지 않으면 7.0 버전부터는 디폴트로 1개의 샤드로 인덱스가 구성되며 6.x 이하 버전에서는 5개로 구성.
클러스터에 노드를 추가하게 되면 샤드들이 각 노드들로 분산되고 디폴트로 1개의 복제본을 생성되고, 만약 노드가 1개만 있는 경우 프라이머리 샤드만 존재하고 복제본은 생성되지 않음.
처음 생성된 샤드를 프라이머리 샤드(Primary Shard), 복제본은 리플리카(Replica) 라고 부르며, 프라이머리 샤드가 요청을 처리한다.
예를 들어 한 인덱스가 5개의 샤드로 구성어 있고, 클러스터가 4개의 노드로 구성되어 있다고 가정하면 각각 5개의 프라이머리 샤드와 복제본, 총 10개의 샤드들이 전체 노드에 골고루 분배되어 저장.
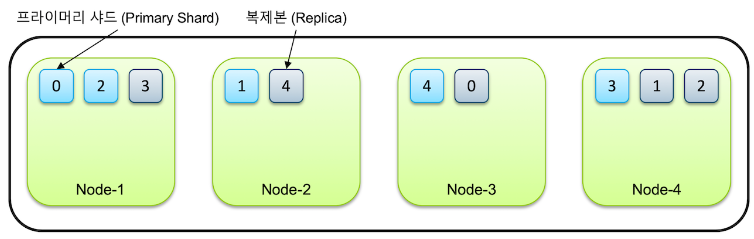
같은 샤드와 복제본은 동일한 데이터를 담고 있으며 반드시 서로 다른 노드에 저장되고, 특정 노드가 시스템 다운되거나 네트워크 단절등으로 내려가면 해당 노드의 샤드는 유실된다. 하지만 다른 노드에 남은 데이터는 사용할 수 있으므로 전체 데이터 유실은 되지 않는다. 프라이머리 샤드가 유실된 경우에는 새로 프라이머리 샤드가 생성되는 것이 아니라, 남아있던 복제본이 먼저 프라이머리 샤드로 승격이 되고 다른 노드에 새로 복제본을 생성하게 된다.
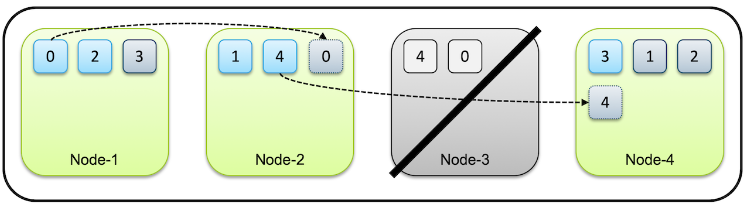
샤드 개수는 인덱스를 처음 생성할 때 지정하며, 인덱스를 재색인하지 않는 이상 변경할 수 없다.
세그먼트
샤드의 데이터를 가지고 있는 물리적인 파일.
샤드에서 검색 시, 먼저 각 세그먼트를 검색하여 결과를 조합한 후 최종 결과를 해당 샤드의 결과로 반환하게 된다. 이때 세그먼트는 내부에 색인된 데이터가 역색인 구조로 저장되어 있으므로 검색 속도가 매우 빠르다.
색인 작업이 요청될 때 인메모리 버퍼에 데이터를 쌓고 일정시간이 지나거나 버퍼가 가득하면 flush 작업이 수행되고 시스템 캐시에 저장된다. 시스템 캐시에 저장된 시점 부터 검색이 가능해진다.
시스템 캐시 데이터는 일정 시간이 지나면 commit 되어 디스크에 세그먼트가 저장된다. 저장된 세그먼트는 시간이 지날수록 하나로 병합(Merge)하는 과정을 수행하는데 이는 검색 성능을 향상시킨다.
위 작업들은 루씬의 내부 메커니즘이며 Elasticsearch에서 자동으로 루씬의 내부 메커니즘을 실행하지만 수동으로 수행할 수 있는 API를 제공하고 있음.
Elasticsearch : 루씬
Refresh: Flush
Flush: Commit
Optimize : Merge
엘라스틱서치 7버전 이후에는 검색 요청이 없는 경우 refresh를 호출하지 않기 때문에 색인 이후 refresh API를 client에서 직접 호출하면 응답지연이 발생하지 않는다고 함.
Elasticsearch 데이터 처리
Elasticsearch의 데이터는 json 형식으로 저장된다.
6.x 이전
http://<호스트>:<포트>/<인덱스>/<도큐먼트 타입>/<도큐먼트 id>
Elasticsearch 7 이후 도큐먼트 타입이 삭제되고 _doc 고정
http://<호스트>:<포트>/<인덱스>/_doc/<도큐먼트 id>
Rest API 공식 문서: https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html
입력 예시
$ curl -X PUT "http://localhost:9200/my_index/_doc/1" -H 'Content-Type: application/json' -d'
{
"name": "Jongmin Kim",
"message": "안녕하세요 Elasticsearch"
}'
{"_index":"my_index","_type":"_doc","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1}
실수로 기존 도큐먼트가 덮어씌워지는 것을 방지하기 위해서는 입력 명령에 _doc 대신 _create 를 사용해서 새로운 도큐먼트의 입력만 허용하는 것이 가능
PUT my_index/_create/1
{
"name":"Jongmin Kim",
"message":"안녕하세요 Elasticsearch"
}
bulk 입력
벌크 동작은 개별 수행하는 것 보다 속도가 훨씬 빠르기 때문에 대량의 데이터를 입력 할 때는 반드시 _bulk API를 사용해야 불필요한 오버헤드가 없다. Logstash 와 Beats 그리고 Elastic 웹페이지에서 제공하는 대부분의 언어별 클라이언트에서는 데이터를 입력할 때 _bulk를 사용하도록 개발되어 있다고 한다.
커밋이나 롤백 등의 트랜잭션 개념이 없기 때문에 bulk 작업 중 연결이 끊어지거나 시스템이 다운되는 등의 이유로 동작이 중단 된 경우에는 어느 동작까지 실행되었는지 확인이 불가능하다. 보통 이런 경우 전체 인덱스를 삭제하고 처음부터 다시 하는 것이 안전하다.
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
{
"took": 30,
"errors": false,
"items": [
{
"index": {
"_index": "test",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 201,
"_seq_no" : 0,
"_primary_term": 1
}
},
{
"delete": {
"_index": "test",
"_id": "2",
"_version": 1,
"result": "not_found",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 404,
"_seq_no" : 1,
"_primary_term" : 2
}
},
{
"create": {
"_index": "test",
"_id": "3",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 201,
"_seq_no" : 2,
"_primary_term" : 3
}
},
{
"update": {
"_index": "test",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 200,
"_seq_no" : 3,
"_primary_term" : 4
}
}
]
}
POST _bulk
{"index":{"_index":"test", "_id":"1"}}
{"field":"value one"}
{"index":{"_index":"test", "_id":"2"}}
{"field":"value two"}
{"delete":{"_index":"test", "_id":"2"}}
{"create":{"_index":"test", "_id":"3"}}
{"field":"value three"}
{"update":{"_index":"test", "_id":"1"}}
{"doc":{"field":"value two"}}
{
"took" : 440,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
...
조회 예시
GET my_index/_doc/1
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Jongmin Kim",
"message" : "안녕하세요 Elasticsearch"
}
}
인덱스에 도큐먼트가 존재하지 않는 경우
GET my_index/_doc/1
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"found" : false
}
인덱스가 없는 경우
GET my_index/_doc/1
{
"error" : {
"root_cause" : [
{
"type" : "index_not_found_exception",
"reason" : "no such index [my_index]",
"resource.type" : "index_expression",
"resource.id" : "my_index",
"index_uuid" : "_na_",
"index" : "my_index"
}
],
"type" : "index_not_found_exception",
"reason" : "no such index [my_index]",
"resource.type" : "index_expression",
"resource.id" : "my_index",
"index_uuid" : "_na_",
"index" : "my_index"
},
"status" : 404
}
업데이트 예시 (PUT / POST 가능)
POST my_index/_doc
{
"name":"Jongmin Kim",
"message":"안녕하세요 Elasticsearch"
}
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "ZuFv12wBspWtEG13dOut",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
안전한 업데이트 예시
POST test/_update/1
{
"script" : {
"source": "ctx._source.counter += params.count",
"lang": "painless",
"params" : {
"count" : 4
}
}
}
여러건 업데이트
POST my-index-000001/_update_by_query?conflicts=proceed
도큐먼트 삭제 예시
DELETE my_index/_doc/1
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
인덱스 삭제 예시
DELETE my_index
{
"acknowledged" : true
}
검색 API
_search 뒤에 q 파라메터를 사용해서 검색어를 입력할 수 있습니다. 이렇게 요청 주소에 검색어를 넣어 검색하는 방식을 URI 검색이라고 한다.
GET test/_search?q=value
두 개의 검색어 “value” 그리고 “three” 를 AND 조건으로 검색 하려면 아래와 같이 조회한다. 그리고 URI 쿼리에서는 AND, OR, NOT 의 사용이 가능하며 반드시 모두 대문자로 입력해야한다.
GET test/_search?q=value AND three
검색어 value 을 field 필드에서 찾고 싶으면 다음과 같이 <필드명>:<검색어> 형태로 입력
GET test/_search?q=field:value
데이터 본문에서 검색
QueryDSL 쿼리 입력은 항상 query 지정자로 시작하고 그 다음 레벨에서 쿼리의 종류를 지정하는데 위에서는 match 쿼리를 지정
GET test/_search
{
"query": {
"match": {
"field": "value"
}
}
}
여러 인덱스에서 검색
GET logs-2018-01,2018-02,2018-03/_search
GET logs-2018-*/_search
GET _all/_search // 시스템 부하 발생하므로 사용 하지 말것.
검색과 쿼리(QqueryDSL)
인터넷 쇼핑몰에 상품이 100만개가 있을 때 검색창에 “무선 이어폰” 이라고 입력해서 시스템에 있는 전체 100만개의 상품들 중 무선 이어폰과 연관된 상품만 추려내는 과정을 검색이라고 할 수 있습니다. 검색 엔진 설정에 따라 상품명이 정확히 “무선 이어폰” 인 것만 보여줄지, “소니 무선 이어폰” 처럼 전체 상품명 중에 검색어를 포함하기만 하면 보여줄지, 가격, 출시일 등과 같이 다른 조건들에 대해서는 어떻게 영향을 받도록 할 것인지 등을 결정할 수 있을 것입니다.
상품명이 정확히 “무선 이어폰” 인 것만 검색 하도록 조건을 엄격하게 하면 표시되는 결과 수가 적어져서 내가 찾는 상품이 나타나지 않을 수 있을 것입니다. 반대로 상품 설명에 “무선” 과 “이어폰” 이 하나라도 있는 상품을 모두 검색하도록 하면 “무선 리모컨”, “이어폰 케이스” 같은 상품까지 검색이 되면서 결과가 너무 많아져서 내가 찾는 상품이 묻혀 버릴 수 있을 것입니다. 품질이 높은 검색 시스템을 구현하기 위해서는 이렇게 많은 부분들을 고민해야 합니다.
Elasticsearch 는 데이터를 실제로 검색에 사용되는 검색어인 텀(Term) 으로 분석 과정을 거쳐 저장하기 때문에 검색 시 대소문자, 단수나 복수, 원형 여부와 상관 없이 검색이 가능하다. 이러한 Elasticsearch의 특징을 풀 텍스트 검색(Full Text Search) 이라고 하며 한국어로 전문 검색 이라고도 한다.
term, match, match_phrase 차이
term: 입력한 단어가 색인에 있는지 검색한다.
match: 입력한 단어를 analyze한 다음 색인에 있는지 검색한다. analyze한 토큰이 하나라도 색인에 있다면 해당 document가 검색된다.
match_phrase: 입력한 단어를 analyze한 다음 색인에 있는지 검색한다. analyze한 토큰이 모두 색인에 있다면 해당 document가 검색된다.
match_all
검색 시 쿼리를 넣지 않으면 elasticsearch는 자동으로 match_all을 적용해서 해당 인덱스의 모든 도큐먼트를 검색한다.
GET my_index/_search
match
match 쿼리는 풀 텍스트 검색에 사용되는 가장 일반적인 쿼리
GET my_index/_search
{
"query": {
"match": {
"message": "dog"
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 0.35847884,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.35847884,
"_source" : {
"message" : "Lazy jumping dog"
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.32951736,
"_source" : {
"message" : "Brown fox brown dog"
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.23470737,
"_source" : {
"message" : "The quick brown fox jumps over the lazy dog"
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.23470737,
"_source" : {
"message" : "The quick brown fox jumps over the quick dog"
}
}
]
}
}
match 검색에 여러 개의 검색어를 집어넣게 되면 디폴트로 OR 조건으로 검색이 되어 입력된 검색어 별로 하나라도 포함된 모든 문서를 모두 검색
GET my_index/_search
{
"query": {
"match": {
"message": "quick dog"
}
}
}
검색어가 여럿일 때 검색 조건을 OR 가 아닌 AND 로 바꾸려면 operator 옵션을 사용할 수 있다.
quick 또는 dog와 일치하는 결과를 얻는다.
GET my_index/_search
{
"query": {
"match": {
"message": {
"query": "quick dog",
"operator": "and"
}
}
}
}
match_phrase
lazy dog 에서 공백까지 포함하여 정확하게 일치하는 내용을 검색한다.
GET my_index/_search
{
"query": {
"match_phrase": {
"message": "lazy dog"
}
}
}
slop이라는 옵션으로 quick 과 dog 사이에 포함될 수 있는 단어 수를 지정할 수도 있다.
GET my_index/_search
{
"query": {
"match_phrase": {
"message": {
"query": "lazy dog",
"slop": 1
}
}
}
}
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0110221,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0110221,
"_source" : {
"message" : "Lazy jumping dog"
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.9489645,
"_source" : {
"message" : "The quick brown fox jumps over the lazy dog"
}
}
]
}
}
query_string
URL의 q 파라메터를 이용해서 검색을 수행할 때와 마찬가지로 루씬 검색 문법을 이용할 수 있다.
GET my_index/_search
{
"query": {
"query_string": {
"default_field": "message",
"query": "(jumping AND lazy) OR \"quick dog\""
}
}
}
Bool Query
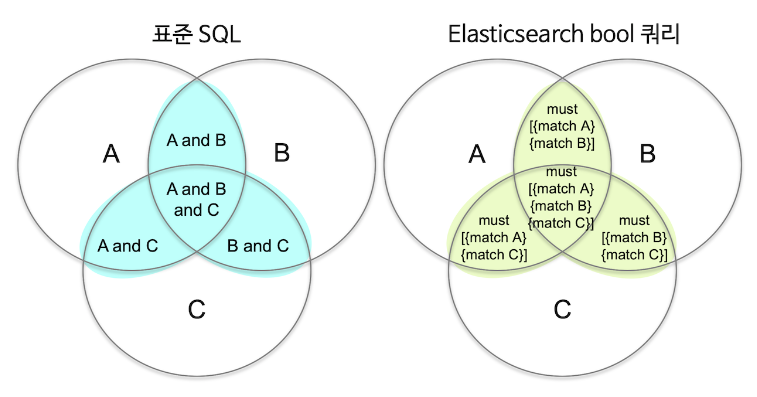
query_string 쿼리는 여러 조건을 조합하기에는 용이한 문법이지만 옵션이 한정되어 있다. 검색에서 여러 쿼리를 조합하기 위해서는 상위에 bool 쿼리를 사용하고 그 안에 다른 쿼리들을 넣는 식으로 사용이 가능하다.
must : 쿼리가 참인 도큐먼트들을 검색
must_not : 쿼리가 거짓인 도큐먼트들을 검색.
should : 검색 결과 중 이 쿼리에 해당하는 도큐먼트의 점수를 높인다
filter : 쿼리가 참인 도큐먼트를 검색하지만 스코어를 계산하지 않고, must 보다 검색 속도가 빠르고 캐싱이 가능.
GET <인덱스명>/_search
{
"query": {
"bool": {
"must": [
{ <쿼리> }, …
],
"must_not": [
{ <쿼리> }, …
],
"should": [
{ <쿼리> }, …
],
"filter": [
{ <쿼리> }, …
]
}
}
}
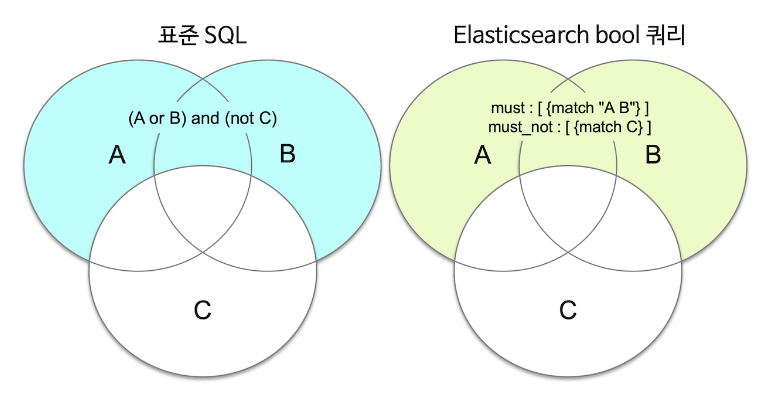
다음은 단어 “quick”과 구문 “lazy dog”가 포함된 모든 문서를 검색하는 쿼리
GET my_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "quick"
}
},
{
"match_phrase": {
"message": "lazy dog"
}
}
]
}
}
}
Relevancy(정확도)
RDB에서는 쿼리 조건에 부합하는 지만 판단하여 결과를 가져올 뿐 각 결과들이 얼마나 정확한지에 대한 판단은 보통 불가능하다. Elasticsearch 와 같은 풀 텍스트 검색엔진은 검색 결과가 입력된 검색 조건과 얼마나 정확하게 일치하는 지를 계산하는 알고리즘을 가지고 있어 이 정확도를 기반으로 사용자가 가장 원하는 결과를 먼저 보여줄 수 있는데 이와 같이 정확한 정도를 relevancy 라고 한다.
스코어 (score) 점수
Elasticsearch의 검색 결과에는 얼마나 검색 조건과 일치하는지를 나타내는 스코어 점수가 표시가 되는데 높은 순으로 결과를 보여준다.
GET my_index/_search
{
"query": {
"match": {
"message": "quick dog"
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 0.8762741,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.8762741,
"_source" : {
"message" : "The quick brown fox jumps over the quick dog"
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.6744513,
"_source" : {
"message" : "The quick brown fox jumps over the lazy dog"
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.6173784,
"_source" : {
"message" : "The quick brown fox"
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.35847884,
"_source" : {
"message" : "Lazy jumping dog"
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.32951736,
"_source" : {
"message" : "Brown fox brown dog"
}
}
]
}
}
Elasticsearch 는 이 점수를 계산하기 위해 BM25(BM은 Best Matching) 라는 알고리즘을 이용한다.
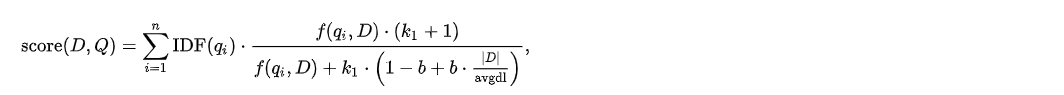
이 계산에는 크게 TF, IDF 그리고 Field Length 총 3가지 요소가 사용된다.
- TF (Term Frequency) : 도큐먼트 내에 검색된 텀(term)이 더 많을 수록 점수가 높아지는 것. (최대 25)
- 축구라고 검색하면 축구가 5개 포함된 도큐먼트보다 10개 포함된 도큐먼트가 점수가 높다.
- IDF (Inverse Document Frequency): 검색된 도큐먼트 개수가 많을 수록 해당 텀의 점수가 감소하는 것.
- 60계 치킨이라고 검색하면 60계로 검색된 도큐먼트가 5개, 치킨으로 검색된 도큐먼트가 100개라고 한다면 60계 텀이 치킨 텀보다 점수가 높게 나온다.
- Field Length: 도큐먼트에서 필드 길이가 큰 필드 보다는 짧은 필드에 있는 텀의 비중이 큰 것.
- “world”로 검색된 도큐먼트가 “hello world”와 “world”이 있다면 “world”가 점수가 높음.
should
검색 결과에서 특정 단어가 포함된 결과에 가중치를 줘서 상위로 올리고 싶다면 should를 사용하면 된다.
fox 결과에 lazy가 포함된 결과를 상위로 올리기
GET my_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "fox"
}
}
],
"should": [
{
"match": {
"message": "lazy"
}
}
]
}
}
}
should는 match_phrase 와 함께 유용하게 사용할 수 있다.
lazy 또는 dog 중 하나라 포함된 도큐먼트를 모두 검색하면서 그 중에 “lazy dog” 구문을 정확히 포함하는 결과들을 가장 상위로 가져온다. must 안에 match 쿼리로 lazy 또는 dog가 포함된 모든 도큐먼트를 검색하고 should 안에 match_phrase 쿼리를 써서 스코어 점수를 높인다.
GET my_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": {
"query": "lazy dog"
}
}
}
],
"should": [
{
"match_phrase": {
"message": "lazy dog"
}
}
]
}
}
}
filter
풀 텍스트와 상반되는 이 특성을 정확값(Exact Value) 이라고 하는데 말 그대로 값이 정확히 일치 하는지의 여부 만을 따지는 검색
filter 안에 넣은 검색 조건들은 스코어를 계산하지 않지만 캐싱이 되기 때문에 쿼리가 더 가볍고 빠르게 실행된다.
Exact Value 에는 term, range 와 같은 쿼리들이 이 부분에 속하며, 스코어를 계산하지 않기 때문에 보통 bool 쿼리의 filter 내부에서 사용하게 된다.
GET my_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "fox"
}
}
],
"filter": [
{
"match": {
"message": "quick"
}
}
]
}
}
}
filter 내부에서 must_not 과 같은 다른 bool 쿼리를 포함하려면 filter 내부에 bool 쿼리를 먼저 넣고 그 안에 다시 must_not 을 넣어야 합니다. 다음은 fox 를 포함하면서 dog 는 포함하지 않는 도큐먼트를 검색하는 쿼리입니다. dog 를 제외하는 must_not 쿼리가 filter 안에 있기 때문에 스코어는 fox 에만 영향을 받습니다.
GET my_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "fox"
}
}
],
"filter": [
{
"bool": {
"must_not": [
{
"match": {
"message": "dog"
}
}
]
}
}
]
}
}
}
message 필드값이 “Brown fox brown dog” 문자열과 공백, 대소문자까지 정확히 일치하는 데이터만을 결과로 리턴합니다.
GET my_index/_search
{
"query": {
"bool": {
"filter": [
{
"match": {
"message.keyword": "Brown fox brown dog"
}
}
]
}
}
}
range(범위)
숫자나 날짜 형식들의 데이터들은 range 쿼리를 이용해서 검색을 한다.
gte (Greater-than or equal to) - 이상 (같거나 큼)
gt (Greater-than) – 초과 (큼)
lte (Less-than or equal to) - 이하 (같거나 작음)
lt (Less-than) - 미만 (작음)
price 필드 값이 700 이상, 900 미만인 데이터를 검색
GET phones/_search
{
"query": {
"range": {
"price": {
"gte": 700,
"lt": 900
}
}
}
}
기본적으로 Elasticsearch 에서 날짜 값은 2016-01-01 또는 2016-01-01T10:15:30 과 같이 JSON 에서 일반적으로 사용되는 ISO8601 형식을 사용한다.
2016년 1월 1일 이후인 도큐먼트들을 검색하는 쿼리
GET phones/_search
{
"query": {
"range": {
"date": {
"gt": "2016-01-01"
}
}
}
}
쿼리의 날짜 포맷을 다르게 하고 싶으면 format 옵션의 사용이 가능하고, || 을 사용해서 여러 값의 입력이 하다. 아래는 date 필드의 값이 2015년 12월 31일 부터 2018년 이전 사이에 있는 값들을 검색하는 쿼리
GET phones/_search
{
"query": {
"range": {
"date": {
"gt": "31/12/2015",
"lt": "2018",
"format": "dd/MM/yyyy||yyyy"
}
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "phones",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"model" : "Samsung GalaxyS 7",
"price" : 859,
"date" : "2016-02-21"
}
},
{
"_index" : "phones",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"model" : "Samsung GalaxyS 8",
"price" : 959,
"date" : "2017-03-29"
}
},
{
"_index" : "phones",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"model" : "Samsung GalaxyS 9",
"price" : 1059,
"date" : "2018-02-25"
}
}
]
}
}
데이터 색인과 텍스트 분석
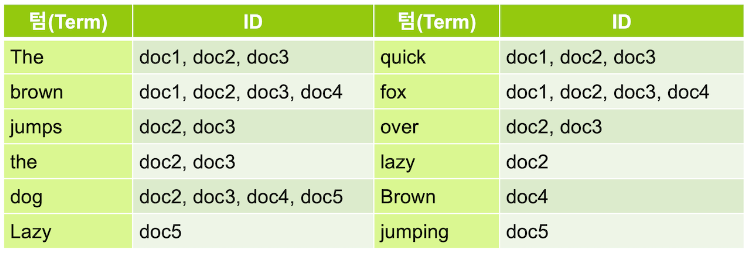
역 인덱스 - Inverted Index
RDB 에서는 아래와 같이 like 검색을 사용하기 때문에 데이터가 늘어날수록 검색해야 할 대상이 늘어나 시간도 오래 걸리고, row 안의 내용을 모두 읽어야 하기 때문에 기본적으로 속도가 느리다.

Elasticsearch는 데이터를 저장할 때 다음과 같이 역 인덱스(inverted index)라는 구조를 만들어 저장하기 때문에 검색이 빠르다.
References:
https://esbook.kimjmin.net/
https://www.elastic.co/guide/index.html
https://steady-coding.tistory.com/573
댓글남기기