Elasticsearch 알아보기 - 2편
텍스트 분석 - Text Analysis
Elasticsearch는 문자열 필드가 저장될 때 데이터에서 검색어 토큰을 저장하기 위해 여러 단계의 처리 과정을 거치는데 이 전체 과정을 텍스트 분석(Text Analysis) 이라고 하고 이 과정을 처리하는 기능을 애널라이저(Analyzer) 라고 한다. Elasticsearch의 애널라이저는 0~3개의 캐릭터 필터(Character Filter)와 1개의 토크나이저(Tokenizer), 그리고 0~n개의 토큰 필터(Token Filter)로 이루어 진다.
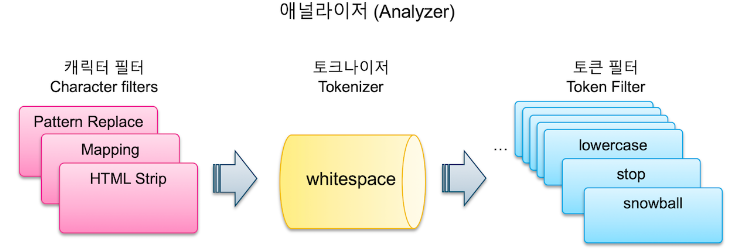
캐릭터 필터: 전체 문장에서 특정 문자를 대치하거나 제거하는 과정
토크나이저: 문장에 속한 단어들을 텀 단위로 하나씩 분리 하는 과정
토큰 필터: 분리된 텀 들을 하나씩 가공하는 과정을 거치는데 이 과정
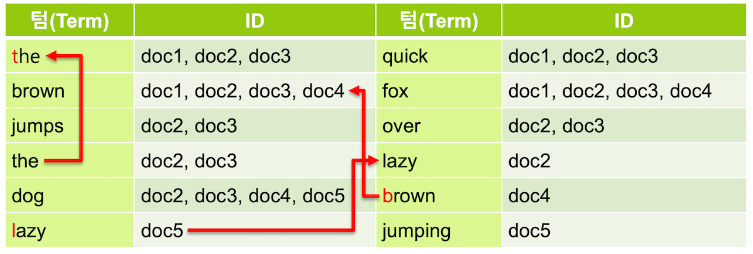
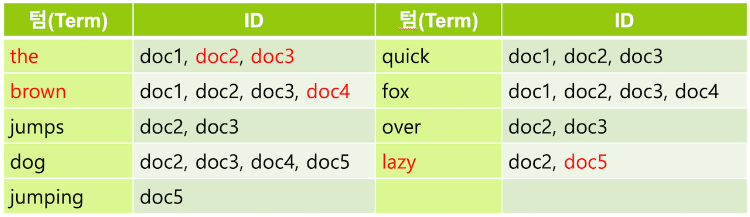
텀 중에는 검색어로서의 가치가 없는 단어들이 있는데 이런 단어를 불용어(stopword) 라고 한다. 보통 a, an, are, at, be, but, by, do, for, i, no, the, to … 등의 단어들은 불용어로 간주되어 검색어 토큰에서 제외된다.
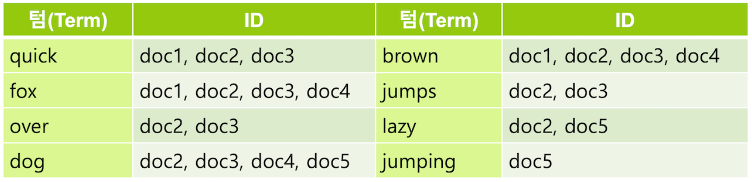
영어에서는 형태소 분석을 위해 snowball 토큰 필터를 주로 사용하는데 이 필터는 ~s, ~ing 등을 제거하고, happy, lazy 와 같은 단어들은 happiness, laziness와 같은 형태로도 사용되기 때문에 ~y 를 ~i 로 변경한다.
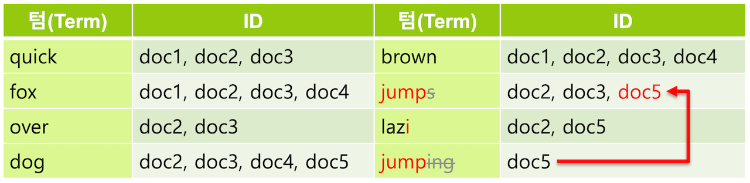
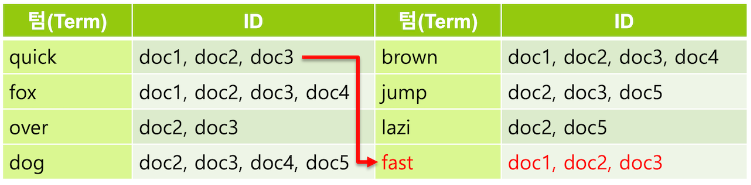
필요에 따라서 synonym 토큰 필터를 사용하여 동의어를 추가 해 주기도 한다. quick 텀에 동의어로 fast를 지정하면 fast 로 검색했을 때도 같은 의미인 quick 을 포함하는 도큐먼트가 검색되도록 할 수 있다.
애널라이저 (Analyzer)
_analyze API
Elasticsearch 에서는 분석된 문장을 _analyze API를 이용해서 확인할 수 있다.
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"stop",
"snowball"
]
}
stop 토큰 필터를 lowercase 보다 먼저 놓게 되면 stop 토큰필터 처리시 대문자로 시작하는 “The”는 stopword(불용어)로 간주되지 않아 그냥 남아있게 된다.
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer": "whitespace",
"filter": [
"stop",
"lowercase",
"snowball"
]
}
snowball 애널라이저를 사용한 결과는 앞의 whitespace 토크나이저 그리고 lowercase, stop, snowball 토큰필터를 사용한 결과와 동일하게 나온다.
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"analyzer": "snowball"
}
인덱스에 애널라이저 적용 예
PUT my_index2
{
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "snowball"
}
}
}
}
위에서 생성한 인덱스에 "message": "The quick brown fox jumps over the lazy dog" 값을 넣고, match 쿼리로 jump, jumping 또는 jumps 중 어떤 값으로 검색 해도 결과가 나타난다.
GET my_index2/_search
{
"query": {
"match": {
"message": "jumping"
}
}
}

사용자 정의 애널라이저
_analyze API로 애널라이저, 토크나이저, 토큰필터들의 테스트가 가능하지만, 실제로 인덱스에 저장되는 데이터의 처리에 대한 설정은 애널라이저만 적용할 수 있습니다. 인덱스 매핑에 애널라이저를 적용 할 때 보통은 이미 정의되어 제공되는 애널라이저 보다는 토크나이저, 토큰필터 등을 조합하여 만든 사용자 정의 애널라이저(Custom Analyzer)를 주로 사용한다.
인덱스에 custom 애널라이저를 등록한다.
PUT my_index3
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"stop",
"snowball"
]
}
}
}
}
}
}
custom 애널라이저를 사용한다.
GET my_index3/_analyze
{
"analyzer": "my_custom_analyzer",
"text": [
"The quick brown fox jumps over the lazy dog"
]
}
custom 애널라이저에 custom 토큰 필터 사용하기
PUT my_index3
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"my_stop_filter",
"snowball"
]
}
},
"filter": {
"my_stop_filter": {
"type": "stop",
"stopwords": [
"brown"
]
}
}
}
}
}
}
my_custom_analyzer를 사용해서 텍스트를 분석 해 보면 brown이 stopword(불용어) 처리가 되어 사라진다
GET my_index3/_analyze
{
"analyzer": "my_custom_analyzer",
"text": [
"The quick brown fox jumps over the lazy dog"
]
}
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "quick",
"start_offset" : 4,
"end_offset" : 9,
"type" : "word",
"position" : 1
},
{
"token" : "fox",
"start_offset" : 16,
"end_offset" : 19,
"type" : "word",
"position" : 3
},
{
"token" : "jump",
"start_offset" : 20,
"end_offset" : 25,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 26,
"end_offset" : 30,
"type" : "word",
"position" : 5
},
{
"token" : "the",
"start_offset" : 31,
"end_offset" : 34,
"type" : "word",
"position" : 6
},
{
"token" : "lazi",
"start_offset" : 35,
"end_offset" : 39,
"type" : "word",
"position" : 7
},
{
"token" : "dog",
"start_offset" : 40,
"end_offset" : 43,
"type" : "word",
"position" : 8
}
]
}
매핑에 사용자 정의 애널라이저 적용
PUT my_index3
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"my_stop_filter",
"snowball"
]
}
},
"filter": {
"my_stop_filter": {
"type": "stop",
"stopwords": [
"brown"
]
}
}
}
}
},
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
}
}
message 필드에 입력되는 값이 필터되는지 확인
PUT my_index3/_doc/1
{
"message": "The quick brown fox jumps over the lazy dog"
}
GET my_index3/_search
{
"query": {
"match": {
"message": "brown"
}
}
}
-- brown은 불용어 처리 되었으므로 검색되지 않음.
{
"took" : 468,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
Term 쿼리
match 쿼리와 문법은 유사하지만 term 쿼리는 입력한 검색어는 애널라이저를 적용하지 않고 입력된 검색어 그대로 일치하는 텀을 찾는다.
jumps, jumping 으로 검색하면 결과가 나타나지 않고 jump로 검색해야 결과가 나타난다. 따라서 도큐먼트의 원문은 jumps 이지만 어떤 쿼리를 사용하느냐에 따라 원문과 같은 jumps 검색어를 넣어도 검색이 되지 않는 경우가 있다.
GET my_index2/_search
{
"query": {
"term": {
"message": "jump"
}
}
}
텀 백터 (_termvectors) API
색인된 도큐먼트의 역 인덱스를 확인할 때 사용함.
7 버전 이후
GET <인덱스>/_termvectors/<도큐먼트id>?fields=<필드명>
6.x 이전
GET <인덱스>/<도큐먼트 타입>/<도큐먼트id>/_termvectors?fields=<필드명>
여러개의 필드를 같이 확인하고 싶을 때는
?fields=field1,field2처럼 쉼표로 나열
사용예
GET my_index3/_termvectors/1?fields=message
{
"_index" : "my_index3",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"found" : true,
"took" : 1,
"term_vectors" : {
"message" : {
"field_statistics" : {
"sum_doc_freq" : 7,
"doc_count" : 1,
"sum_ttf" : 8
},
"terms" : {
"dog" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 8,
"start_offset" : 40,
"end_offset" : 43
}
]
},
"fox" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 3,
"start_offset" : 16,
"end_offset" : 19
}
]
},
"jump" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 4,
"start_offset" : 20,
"end_offset" : 25
}
]
},
"lazi" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 7,
"start_offset" : 35,
"end_offset" : 39
}
]
},
"over" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 5,
"start_offset" : 26,
"end_offset" : 30
}
]
},
"quick" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 4,
"end_offset" : 9
}
]
},
"the" : {
"term_freq" : 2,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 3
},
{
"position" : 6,
"start_offset" : 31,
"end_offset" : 34
}
]
}
}
}
}
}
캐릭터 필터 (Character Filter)
캐릭터 필터는 텍스트 분석 중 가장 먼저 처리되는 과정으로 색인된 텍스트가 토크나이저에 의해 텀으로 분리되기 전에 전체 문장에 대해 적용되는 일종의 전처리 도구이다. 7.0 버전 기준으로 캐릭터 필터는 HTML Strip, Mapping, Pattern Replace 총 3개가 존재한다.
HTML Strip
입력된 텍스트에서 HTML 태그들을 제거하여 일반 텍스트로 만든다. 아래 예는 모든 태그들이 제거되고 해석되어 “I’m so happy!” 라는 문장으로 변경된다.
POST _analyze
{
"tokenizer": "keyword",
"char_filter": [
"html_strip"
],
"text": "<p>I'm so <b>happy</b>!</p>"
}
{
"tokens" : [
{
"token" : """
I'm so happy!
""",
"start_offset" : 0,
"end_offset" : 32,
"type" : "word",
"position" : 0
}
]
}
애널라이저는 항상 최소 1개의 토크나이저를 필요로 하기 때문에 캐릭터 필터만 적용하면 오류가 발생한다.
Mapping
Mapping 캐릭터 필터를 이용하면 지정한 단어를 다른 단어로 치환이 가능하며 특수문자 등을 포함하는 검색 기능을 구현하려는 경우 반드시 적용해야 해서 실제로 캐릭터 필터 중에는 가장 많이 쓰인다.
아래와 같이 C++을 검색하면 C와 C++이 검색된다. 그 이유는 도큐먼트가 색인될 때 strandard 애널라이저가 적용되면서 C++에서 특수문자가 제거 되고 C만 텀으로 저장되기 때문이다.
GET coding/_search
{
"query": {
"match": {
"language": "C++"
}
}
}
standard 뿐 아니라 대다수의 애널라이저들이 특수문자에 대해서는 stopword(불용어)로 간주하고 제거 해 버리기 때문에 특수문자가 포함된 검색어들을 검색하려면 먼저 특수문자를 다른 문자로 치환해서 저장해야 한다.
PUT coding
{
"settings": {
"analysis": {
"analyzer": {
"coding_analyzer": {
"char_filter": [
"cpp_char_filter"
],
"tokenizer": "whitespace",
"filter": [ "lowercase", "stop", "snowball" ]
}
},
"char_filter": {
"cpp_char_filter": {
"type": "mapping",
"mappings": [ "+ => _plus_", "- => _minus_" ]
}
}
}
},
"mappings": {
"properties": {
"language": {
"type": "text",
"analyzer": "coding_analyzer"
}
}
}
}
match 쿼리로 검색을 하면 검색어 C++ 역시 동일한 애널라이저가 적용되어 c_plus__plus_ 로 바뀌어 검색되기 때문에 텀 c_plus__plus_ 가 해당되는 "_id" : "3" 도큐먼트만 검색이 된다.

Pattern Replace
Pattern Replace 캐릭터 필터는 정규식(Regular Expression)을 이용해서 좀더 복잡한 패턴들을 치환할 수 있는 캐릭터 필터이다.
다음은 카멜 표기법(camelCase)으로 된 단어를 대문자가 시작하는 단위 마다 공백을 삽입하여 세부 단어별로 토크나이징 될 수 있도록 camel 인덱스에 camel_analyzer 라는 애널라이저를 생성하는 예제이다.
PUT camel
{
"settings": {
"analysis": {
"analyzer": {
"camel_analyzer": {
"char_filter": [
"camel_filter"
],
"tokenizer": "standard",
"filter": [
"lowercase"
]
}
},
"char_filter": {
"camel_filter": {
"type": "pattern_replace",
"pattern": "(?<=\\p{Lower})(?=\\p{Upper})",
"replacement": " "
}
}
}
}
}
FooBazBar가 foo, baz, bar 3 개의 텀으로 분리 된다.
GET camel/_analyze
{
"analyzer": "camel_analyzer",
"text": [
"public void FooBazBar()"
]
}
{
"tokens" : [
{
"token" : "public",
"start_offset" : 0,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "void",
"start_offset" : 7,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "foo",
"start_offset" : 12,
"end_offset" : 14,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "baz",
"start_offset" : 15,
"end_offset" : 17,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "bar",
"start_offset" : 18,
"end_offset" : 21,
"type" : "<ALPHANUM>",
"position" : 4
}
]
}
캐릭터 필터는 토크나이저가 적용되기 이전에 해당 필드 전체 내용을 치환하는 일종의 전처리 작업이다. 유사한 기능을 구현하여 적용하더라도 뒤에 나올 토큰필터에서 텀을 처리하는 것과는 결과에 있어 position 같은 값들의 차이가 생긴다.
토크나이저 (Tokenizer)
데이터 색인 과정에서 검색 기능에 가장 큰 영향을 미치는 단계가 토크나이저이다. 데이터 분석 과정에서 토크나이저는 반드시 한 개만 사용이 가능하며 tokenizer 항목에 단일값으로 설정한다.
공식 문서(https://www.elastic.co/guide/en/elasticsearch/reference/7.17/analysis-tokenizers.html)에 보면 아래와 같은 토큰나이저가 있다.
-
Word Oriented Tokenizers
-
Standard Tokenizer : 유니코드 텍스트 분할 알고리즘에 정의된 대로 텍스트 단어를 분리하며, 대부분의 특수문자를 제외한다.
GET _analyze { "tokenizer": "standard", "text": "THE quick.brown_FOx jumped! @ 3.5 meters." } 분할된 5개 토큰: THE, quick.brown_FOx, jumped, 3.5, meters 삭제된 단어: @, ., ! -
Letter Tokenizer: 문자가 아닌 문자를 기준으로 텍스트를 분리하여 토큰화 한다.
GET _analyze { "tokenizer": "letter", "text": "THE quick.brown_FOx jumped! @ 3.5 meters." } 분할된 6개 토큰: THE, quick, brown, FOx, jumped, meters 삭제된 단어: @, _, 3.5, ., ! -
Lowercase Tokenizer: 입력된 텍스트를 소문자로 변환하여 단어 단위로 토큰화 한다.
-
Whitespace Tokenizer: 공백 문자 기준으로 텍스트를 분리하여 토큰화 한다.
GET _analyze { "tokenizer": "whitespace", "text": "THE quick.brown_FOx jumped! @ 3.5 meters." } 분할된 6개 토큰: THE, quick.brown_FOx, jumped!, @, 3.5, meters. 삭제된 단어: 없음 -
UAX URL Email Tokenizer: 텍스트 데이터에서 URL과 이메일 주소를 추출하고 이를 개별 토큰으로 분리하여 색인화하고 검색할 때 사용한다.
standard와 비교
GET _analyze { "tokenizer": "standard", "text": "email address is my-name@email.com and website is https://www.elastic.co" } 분할된 6개 토큰: email, address, is, my, name, email.com, and, website, is, https, www.elastic.co 삭제된 단어: @, ://GET _analyze { "tokenizer": "uax_url_email", "text": "email address is my-name@email.com and website is https://www.elastic.co" } 분할된 6개 토큰: email, address, is, my-name@email.com, and, website, is, https://www.elastic.co 삭제된 단어: 없음 -
Classic Tokenizer: 텍스트를 구두점 및 공백을 기준으로 단어 단위로 토큰화한다.
-
Thai Tokenizer: 태국어 텍스트를 단어 단위로 토큰화한다.
-
-
Partial Word Tokenizers
- N-Gram Tokenizer: 텍스트를 N개의 연속된 문자열로 분리하는 방식(2-Gram으로 Hello를 처리하면 He, el, ll, lo 4개의 토큰으로 분리 된다)
- Edge N-Gram Tokenizer: 단어의 시작 부분에서만 N-그램을 생성하는 방식(H, He, Hel, Hell, Hello)
-
Structured Text Tokenizers
-
Keyword Tokenizer: 텍스트를 분리하지 않고 전체를 하나의 토큰으로 취급한다.( 제품 ID, URL 등)
-
Pattern Tokenizer: 정규 표현식을 기반으로 텍스트를 분리
PUT pat_tokenizer { "settings": { "analysis": { "tokenizer": { "my_pat_tokenizer": { "type": "pattern", "pattern": "/" } } } } } GET pat_tokenizer/_analyze { "tokenizer": "my_pat_tokenizer", "text": "/usr/share/elasticsearch/bin" } 분할된 4개 토큰: usr, share, elasticsearch, bin -
Char Group Tokenizer : 분할할 문자 집합을 구성하고 이를 기반으로 분리한다. 일반적으로 Pattern Tokenizer보다 비용이 작음.
-
Simple Pattern Split Tokenizer
-
Path Tokenizer : 파일 시스템 경로와 같은 계층적 값을 취하고 경로 구분 기호로 분할(예:
/foo/bar/baz→ )[/foo, /foo/bar, /foo/bar/baz ].POST _analyze { "tokenizer": "path_hierarchy", "text": "/usr/share/elasticsearch/bin" } 분할된 토큰: /usr, /usr/share, /usr/share/elasticsearch, /usr/share/elasticsearch/bin치환 후 토큰화 하기
PUT hir_tokenizer { "settings": { "analysis": { "tokenizer": { "my_hir_tokenizer": { "type": "path_hierarchy", "delimiter": "-", "replacement": "/" } } } } } GET hir_tokenizer/_analyze { "tokenizer": "my_hir_tokenizer", "text": [ "one-two-three" ] } 분할된 토큰: one, one/two, one/two/three
-
토큰 필터 (Token Filter)
토크나이저를 이용한 텀 분리 과정 이후에는 분리된 각각의 텀 들을 지정한 규칙에 따라 처리한다.
공식문서 토큰 필터
- Apostrophe
- ASCII folding
- CJK bigram
- CJK width
- Classic
- Common grams
- Conditional
- Decimal digit
- Delimited payload
- Dictionary decompounder
- Edge n-gram
- Elision
- Fingerprint
- Flatten graph
- Hunspell
- Hyphenation decompounder
- Keep types
- Keep words
- Keyword marker
- Keyword repeat
- KStem
- Length
- Limit token count
- Lowercase
- MinHash
- Multiplexer
- N-gram
- Normalization
- Pattern capture
- Pattern replace
- Phonetic
- Porter stem
- Predicate script
- Remove duplicates
- Reverse
- Shingle
- Snowball
- Stemmer
- Stemmer override
- Stop
- Synonym
- Synonym graph
- Trim
- Truncate
- Unique
- Uppercase
- Word delimiter
- Word delimiter graph
너무 많은데…. 그 중에 몇가지만 예로 보자.
lowercase
GET _analyze
{
"filter": [ "lowercase" ],
"text": [ "Harry Potter and the Philosopher's Stone" ]
}
"token" : "harry potter and the philosopher's stone"
uppercase
GET _analyze
{
"filter": [ "uppercase" ],
"text": [ "Harry Potter and the Philosopher's Stone" ]
}
"token" : "HARRY POTTER AND THE PHILOSOPHER'S STONE"
Synonym
PUT my_stop
{
"settings": {
"analysis": {
"filter": {
"my_stop_filter": {
"type": "stop",
"stopwords": [
"in",
"the",
"days"
]
}
}
}
}
}
GET my_stop/_analyze
{
"tokenizer": "whitespace",
"filter": [
"lowercase",
"my_stop_filter"
],
"text": [ "Around the World in Eighty Days" ]
}
"token" : "around", "world", "eighty"
PUT my_synonym
{
"settings": {
"analysis": {
"analyzer": {
"my_syn": {
"tokenizer": "whitespace",
"filter": [
"lowercase",
"syn_aws"
]
}
},
"filter": {
"syn_aws": {
"type": "synonym",
"synonyms": [
"amazon => aws"
]
}
}
}
},
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "my_syn"
}
}
}
}
PUT my_synonym/_doc/1
{ "message" : "Amazon" }
PUT my_synonym/_doc/2
{ "message" : "AWS" }
두개의 텍스트 Amazon과 AWS는 모두 aws 텀이 생성된다.
여러개의 Synonym를 지정해야 된다면 파일로 관리하는 것이 편리하다.
동의어는 하나의 규칙당 한 줄씩 입력해야 하며 파일은 UTF-8로 인코딩 되어야 한다.
$ echo 'quick, fast
hop, jump' > config/user_dic/my_syn_dic.txt
PUT my_synonym
{
"settings": {
"analysis": {
"analyzer": {
"my_syn": {
"tokenizer": "whitespace",
"filter": [
"lowercase",
"syn_aws"
]
}
},
"filter": {
"syn_aws": {
"type": "synonym",
"synonyms_path": "user_dic/my_syn_dic.txt"
}
}
}
},
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "my_syn"
}
}
}
}
"synonym": {
"type": "synonym",
"synonyms": [
"스타벅스, 스벅"
]
}
동의어에 스타벅스와 스벅을 등록하면 다음과 같은 오류가 발생한다.
원인은 스벅이 단어가 아니라 합성어로 인식하기 때문이다.
"caused_by": {
"type": "illegal_argument_exception",
"reason": "term: 스벅 analyzed to a token (벅) with position increment != 1 (got: 2)"
}
이를 회피하기 위해서는 user_dictionary에 해당 단어를 등록해야 한다.
user_dictionary.txt파일을 생성한 다음 단어를 입력하고 저장한다 (UTF-8)
스벅
떡볶이
떡뽁이
라볶이
라뽁이
아메리카노
김밥
통닭
...
docker container로 해당 파일 전송
docker cp /mnt/c/Users/webme/user_dictionary.txt elasticsearch:/usr/share/elasticsearch/config/
Successfully copied 5.63kB to elasticsearch:/usr/share/elasticsearch/config/
docker container에서 확인
# docker exec -itu0 elasticsearch /bin/bash
# cat /usr/share/elasticsearch/config/user_dictionary.txt
NGram
특정한 사용 사례에 따라 텀이 아닌 단어의 일부만 가지고도 검색해야 하는 기능이 필요한 경우가 있다. RDBMS의 LIKE 검색 처럼 사용하는 wildcard 쿼리나 regexp (정규식) 쿼리도 지원을 하지만, 이런 쿼리들은 메모리 소모가 많고 느리다.
이런 사용을 위해 검색 텀의 일부만 미리 분리해서 저장을 할 수 있는데 이렇게 단어의 일부를 나눈 부위를 NGram 이라고 하고 보통은 unigram(유니그램 – 1글자), bigram(바이그램 - 2자) 등으로 부른다.
예를들어 다음과 같은 텀들이 존재한다고 가정해보자.
60계치킨, 양념치킨, 후라이드치킨, 멕시칸치킨
치킨으로 검색하면 검색되지 않을 것이다. 그래서 텀들을 분리하여 저장해 두면 이를 검색할 수 있다.
PUT my_ngram
{
"settings": {
"analysis": {
"filter": {
"my_ngram_f": {
"type": "nGram",
"min_gram": 2,
"max_gram": 3
}
}
}
}
}
GET my_ngram/_analyze
{
"tokenizer": "keyword",
"filter": [
"my_ngram_f"
],
"text": "house"
}
"token" : "ho", "ou", "ous", "us", "use", "se",
그 외 Edge Ngram, Shingle이 있다.
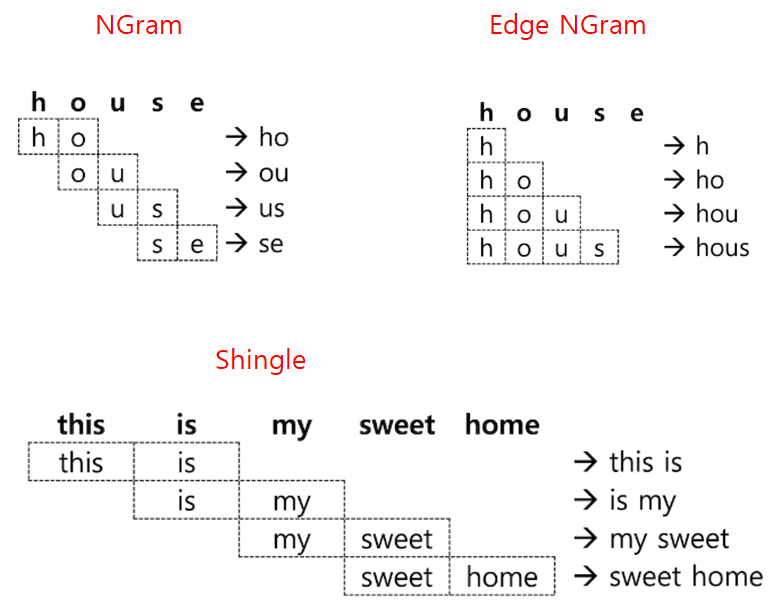
NGram, Edged NGram 그리고 Shingle 토큰 필터는 보통 일반적인 텍스트 분석에 사용하기는 적합하지 않다. 하지만 자동 완성 기능을 구현하거나 프로그램 코드 안에서 문법이나 기능명을 검색하는 것과 같이 특수한 요구사항을 충족해야 하는 경우 유용하게 사용될 수 있다.
Unique
“white fox, white rabbit, white bear” 같은 문장을 분석하면 “white” 텀은 총 3번 저장이 된다. 역 색인에는 텀이 1개만 있어도 텀을 포함하는 도큐먼트를 가져올 수 있기 때문에 unique 토큰 필터를 사용해서 중복되는 텀 들은 하나만 저장하도록 할 수 있다.
GET _analyze
{
"tokenizer": "standard",
"filter": [
"lowercase",
"unique"
],
"text": [
"white fox, white rabbit, white bear"
]
}
match 쿼리를 사용해서 검색하는 경우 unique 토큰 필터를 적용한 필드는 텀의 개수가 1개로 되기 때문에 TF(Term Frequency) 값이 줄어들어 스코어 점수가 달라질 수 있다. match 쿼리를 이용해 정확도(relevancy) 를 따져야 하는 검색의 경우에는 unique 토큰 필터는 사용하지 않는 것이 좋다.
한글 형태소 분석기(Stemmer)
언어별 불용어(https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-stop-tokenfilter.html#analysis-stop-tokenfilter-stop-words-by-lang)에서 _cjk_ (Chinese, Japanese, and Korean) 가 존재하지만 한글은 주로 Nori 분석기를 많이 사용한다고 한다.
Nori 형태소 분석기는 Elasticsearch 6.6 버전 부터 공식적으로 지원하기 시작하였으며 일본어 분석기를 개발한 프랑스 엔지니어가 처음 개발 하였다고 한다.
기본 플러그인으로 포함되어 있지 않기 때문에 직접 수동으로 플러그인해야한다고 한다.
(https://hanamon.kr/elasticsearch-%EA%B2%80%EC%83%89%EC%97%94%EC%A7%84-nori-%ED%98%95%ED%83%9C%EC%86%8C-%EB%B6%84%EC%84%9D%EA%B8%B0-%EA%B2%80%EC%83%89-%EA%B3%A0%EB%8F%84%ED%99%94-%EB%B0%A9%EB%B2%95/)
토크나이저 결과 비교
standard
GET _analyze
{
"tokenizer": "standard",
"text": [
"동해물과 백두산이"
]
}
"token" : "동해물과", "백두산이"
nori_tokenizer
GET _analyze
{
"tokenizer": "nori_tokenizer",
"text": [
"동해물과 백두산이"
]
}
"token" : "동해", "물", "과", "백두", "산", "이"
nori_tokenizer 옵션
user_dictionary : 사용자 사전이 저장된 파일의 상대 경로 지정. 변경 시 인덱스 _close / _open하여 반영.
user_dictionary_rules : 사용자 정의 사전을 배열로 입력.
decompound_mode : 합성어의 저장 방식을 결정.
-
none: 어근을 분리하지 않고 완성된 합성어만 저장. -
discard(디폴트) : 합성어를 분리하여 각 어근만 저장. -
mixed: 어근과 합성어를 모두 저장.
사용 예시
PUT my_nori
{
"settings": {
"analysis": {
"tokenizer": {
"my_nori_tokenizer": {
"type": "nori_tokenizer",
"user_dictionary_rules": [
"해물"
]
}
}
}
}
}
GET my_nori/_analyze
{
"tokenizer": "my_nori_tokenizer",
"text": [
"동해물과"
]
}
"token" : "동", "해물", "과",
nori_tokenizer 기본 옵션으로 “백두산이”를 분석하면 “백두”, “산”, “이”로 분리된다.
“백두산” 은 “백두”+”산” 두 어근이 합쳐진 합성어이기 때문인데, “미역”+”국” “서울”+”역”과 같은 합성어가 존재한다.
decompound_mode 옵션을 이용하면 합성어를 분리하는 방식을 지정할 수 있다.
PUT my_nori
{
"settings": {
"analysis": {
"tokenizer": {
"nori_none": {
"type": "nori_tokenizer",
"decompound_mode": "none"
},
"nori_discard": {
"type": "nori_tokenizer",
"decompound_mode": "discard"
},
"nori_mixed": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
}
}
}
}
GET my_nori/_analyze
{
"tokenizer": "nori_none",
"text": [ "백두산이" ]
}
"token" : "백두산", "이"
GET my_nori/_analyze
{
"tokenizer": "nori_discard",
"text": [ "백두산이" ]
}
"token" : "백두", "산", "이"
GET my_nori/_analyze
{
"tokenizer": "nori_mixed",
"text": [ "백두산이" ]
}
"token" : "백두산", "백두", "산", "이"
nori_part_of_speech
한글 검색에서는 보통 명사, 동명사 정도만을 검색하고 조사, 형용사 등은 제거된다.
nori_part_of_speech 토큰 필터를 이용해서 제거할 품사(POS - Part Of Speech) 정보의 지정이 가능하며, 옵션 stoptags 값에 배열로 제외할 품사 코드를 나열해서 입력해서 사용한다.
stoptags의 디폴트 값은 아래와 같다.
"stoptags": [
"E", "IC", "J", "MAG", "MAJ",
"MM", "SP", "SSC", "SSO", "SC",
"SE", "XPN", "XSA", "XSN", "XSV",
"UNA", "NA", "VSV"
]
수사(NR)를 제거하도록 stoptags를 지정하는 예시
PUT my_pos
{
"settings": {
"index": {
"analysis": {
"filter": {
"my_pos_f": {
"type": "nori_part_of_speech",
"stoptags": [
"NR"
]
}
}
}
}
}
}
GET my_pos/_analyze
{
"tokenizer": "nori_tokenizer",
"filter": [
"my_pos_f"
],
"text": "다섯아이가"
}
"token" : "아이", "가"
“다섯”+”아이”+”가” 로 분석되어야 할 문장에서 수사인 “다섯”이 제거 된 것을 확인할 수 있다.
nori_readingform
한자를 한글로 변환하여 저장하는 기능.
GET _analyze
{
"tokenizer": "nori_tokenizer",
"filter": [
"nori_readingform"
],
"text": "春夏秋冬"
}
"token" : "춘하추동"
인덱스 설정과 매핑
모든 인덱스는 settings 과 mappings 정보를 가지고 있다.
인덱스 생성 후 정보를 확인
PUT my_index
GET my_index
{
"my_index" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1568695052917",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "Ol2vvLbgSfiJcjDC0Eo85A",
"version" : {
"created" : "7030099"
},
"provided_name" : "my_index"
}
}
}
}
개별로 확인하기
GET my_index/_settings
GET my_index/_mappings
number_of_shards, number_of_replicas
number_of_shards : 샤드 수 (default: 7.x는 1개, 6.x 이하 5개)
number_of_replicas: 복제 수
PUT my_index
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
}
아래 처럼 지정할 수도 있음
PUT my_index
{
"settings": {
"index.number_of_shards": 3,
"index.number_of_replicas": 1
}
}
number_of_shards 설정은 인덱스를 처음 생성할 때 한번 지정하면 바꿀 수 없다. 샤드 수를 바꾸려면 새로 인덱스를 정의하고 기존 인덱스의 데이터를 재색인 해야 한다. number_of_replicas 설정은 동적으로 변경이 가능하다.
PUT my_index
{
"settings": {
"refresh_interval": "30s"
}
}
기본적인 인덱스의 캐릭터 필터(Character Filter),토크나이저(Tokenizer), 토큰 필터(Token Filter)는 아래와 같은 구조를 가진다. "analysis": { } 내용은 한번 생성 후 변경은 불가능하다. 이미 만들어진 인덱스에 애널라이저나 토크나이저 등을 추가하거나 사전을 변경하려면 인덱스를 먼저 _close 한 후에 추가하고 다시 _open 해서 적용할 수 있다.
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_flter": [ "...", "..." ... ]
"tokenizer": "...",
"filter": [ "...", "..." ... ]
}
},
"char_filter":{
"my_char_filter":{
"type": "…"
...
}
}
"tokenizer": {
"my_tokenizer":{
"type": "…"
...
}
},
"filter": {
"my_token_filter": {
"type": "…"
...
}
}
}
}
}
동적(Dynamic) 매핑
Elasticsearch 는 동적 매핑을 지원하기 때문에 미리 정의하지 않아도 인덱스에 도큐먼트를 새로 추가하면 자동으로 매핑이 생성된다.
books 인덱스가 없는 상태에서도 입력이 가능하다.
PUT books/_doc/1
{
"title": "Romeo and Juliet",
"author": "William Shakespeare",
"category": "Tragedies",
"publish_date": "1562-12-01T00:00:00",
"pages": 125
}
books 인덱스 확인
GET books/_mapping
{
"books" : {
"mappings" : {
"properties" : {
"author" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"category" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"pages" : {
"type" : "long"
},
"publish_date" : {
"type" : "date"
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
publish_date를 보면 type이 date인 것을 확인할 수 있다.
Elasticsearch 의 매핑이 동적으로 생성 될 때는 필드의 값을 보고 타입을 예상하는데, 항상 그 필드가 포함될 수 있는 가장 넓은 범위 형태의 데이터 타입을 선택한다. pages 필드의 값은 125로 값이 작지만 자연수를 저장하는 데이터 타입 중 가장 큰 long 으로 지정이 되고, publish_date 필드는 값이 “1562-12-01T00:00:00” 로 JSON 도큐먼트에서 사용하는 ISO8601 표준 날짜 형식의 데이터를 준수하였기 때문에 date 타입으로 지정된다. 하지만 날짜가 “1 Dec 1562 00:00:00” 같이 다른 포맷으로 입력이 되면 보통은 text 타입으로 지정된다.
매핑 정의
데이터가 입력되어 자동으로 매핑이 생성되기 전에 미리 먼저 인덱스의 매핑을 정의 해 놓으면 정의 해 놓은 매핑에 맞추어 데이터가 입력된다. 만약 정의되지 않은 필드 값이 들어오면 위에서 설명한 것 처럼 자동 추가 된다.
PUT <인덱스명>
{
"mappings": {
"properties": {
"<필드명>":{
"type": "<필드 타입>"
… <필드 설정>
}
…
}
}
}
이미 만들어진 매핑에 필드를 추가하는것은 가능하지만 이미 만들어진 필드를 삭제하거나 필드의 타입 및 설정값을 변경하는 것은 불가능하다. 따라서 필드의 변경이 필요한 경우 인덱스를 새로 정의하고 기존 인덱스의 값을 새 인덱스에 모두 재색인 해야한다.
새로운 필드 추가
PUT <인덱스명>/_mapping
{
"properties": {
"<추가할 필드명>": {
"type": "<필드 타입>"
… <필드 설정>
}
}
}
추가할 필드명이 기존 필드와 중복되는 이름이면 오류가 발생한다.
Elasticsearch 필드에 설정 가능한 타입
일반적으로 자바 언어 레벨에서 지원하는 기본 타입들과 Elasticsearch 또는 루씬 레벨에서 추상화된 확장 타입들이 있다. 인덱스를 생성할 때 매핑에 필드를 미리 정의하지 않으면 동적 문자열 필드가 생성 될 때 text 필드와 keyword 필드가 다중 필드로 같이 생성된다.
{
"books" : {
"mappings" : {
"properties" : {
"author" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
...
문자 타입
-
text
입력된 문자열을 텀 단위로 쪼개어 역 색인 (inverted index) 구조를 만든다. 보통은 풀텍스트 검색에 사용할 문자열 필드 들을 text 타입으로 지정한다.
설정 가능한 옵션
"analyzer" : "<애널라이저명>"- 색인에 사용할 애널라이저를 입력하며 디폴트로는 standard 애널라이저를 사용한다. 토크나이저, 토큰필터들을 따로 지정할수가 없으며 필요하다면 사용자 정의 애널라이저를 settings에 정의 해 두고 사용해야 한다."search_analyzer" : "<애널라이저명>"- 기본적으로 text 필드는 match 쿼리로 검색을 할 때 색인에 사용한 동일한 애널라이저로 검색 쿼리를 분석한다. search_analyzer 를 지정하면 검색시에는 색인에 사용한 애널라이저가 아닌 다른 애널라이저를 사용하도록 할 수 있으며 보통 NGram 방식으로 색인을 했을 때는 지정 해 주는 것이 좋다."index" : <true | false>- 디폴트는 true 이며 false로 설정하면 해당 필드는 역 색인을 만들지 않아 검색이 불가능하게 된다."boost" : <숫자 값>- 디폴트는 1 이며 값이 1 보다 높으면 풀텍스트 검색 시 해당 필드 스코어 점수에 가중치를 부여한다. 1보다 낮은 값을 입력하면 가중치가 내려간다."fielddata" : <true | false>- 디폴트는 false이며 true로 설정하면 해당 필드의 색인된 텀 들을 가지고 집계(aggregation) 또는 정렬(sorting)이 가능하게 된다. 이 설정은 다이나믹 설정으로 이미 정의된 매핑에 true 또는 false로 다시 적용하는 것이 가능하다. 이 옵션은 쿼리에 메모리 사용량이 많이지기 때문에 일반적으로 설정하지 않는다. 집계와 정렬은 항상 keyword 필드로 사용하는 것을 권장한다. -
keyword
keyword 타입은 입력된 문자열을 하나의 토큰으로 저장합기 때문에 text 타입에 keyword 애널라이저를 적용 한 것과 동일하다. 보통은 집계(aggregation) 또는 정렬(sorting)에 사용할 문자열 필드를 keyword 타입으로 지정한다.
설정 가능한 옵션
index,boost설정은 text 필드와 동일"ignore_above" : <자연수>- 디폴트는 2,147,483,647 이며 다이나믹 매핑으로 생성되면 ignore_above: 256 로 설정이 됩니다. 설정된 길이 이상의 문자열은 색인을 하지 않아 검색이나 집계가 불가능합니다."normalizer" : "<노멀라이저명>"- keyword 필드는 애널라이저를 사용하지 않는 대신 노멀라이저(normalizer) 의 적용이 가능하다. 노멀라이저는 애널라이저와 유사하게 settings 에서 정의하며 토크나이저는 적용할 수 없고 캐릭터 필터와 토큰 필터만 적용해서 사용이 가능하다.
설정 예
PUT blogs
{
"settings": {
"analysis": {
"analyzer": {
"engram_a": {
"tokenizer": "standard",
"filter": [ "lowercase", "engram_f" ]
}
},
"filter": {
"engram_f": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 5
}
},
"normalizer": {
"norm_low": {
"type": "custom",
"filter": [ "lowercase", "asciifolding" ]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"boost": 2,
"fields": {
"keyword": {
"type": "keyword",
"normalizer": "norm_low"
}
}
},
"author": {
"type": "text",
"analyzer": "engram_a",
"search_analyzer": "standard",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"synopsis": {
"type": "text",
"fielddata": true
},
"category": {
"type": "keyword"
},
"content": {
"type": "text",
"index": false
}
}
}
}
숫자 타입
long : 64비트 정수 (-9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807)
integer : 32비트 정수 (-2147483648 ~ 2147483647)
short : 16비트 정수 (-32768 ~ 32767)
byte : 8비트 정수 (-128 ~ 127)
double : 64비트 실수
float : 32비트 실수
half_float : 16비트 실수
scaled_float : 실수형이지만 부동소수점이 아니라 long 형태로 저장하고 옵션으로 소수점 위치를 지정합니다. 통화 (예: $19.99) 같이 소수점 자리가 고정된 값을 표시할 때 유용합니다.
설정 가능한 옵션
"index", "doc_values", "boost" 옵션들은 text, keyword 필드의 옵션들과 동일
"coerce": <true | false> - 디폴트는 true이며 3, 3.4, 3.3 등을 입력하면 모두 자연수 3로 자동으로 변환되어 저장된다. false 로 설정하면 정확한 타입으로 입력되지 않으면 오류가 발생한다.
"null_value" : <숫자값> - 필드값이 입력되지 않거나 null 인 경우 해당 필드의 디폴트 값을 지정.
scaled_float 타입에서만 사용되는 옵션
"scaling_factor" : <10의 배수> - scaled_float 를 사용하려면 필수로 지정해야 하는 옵션이며 소수점 몇 자리까지 저장할지를 지정한다. 12.3456 이라는 값을 저장하는 경우 scaling_factor: 10 으로 설정했으면 실제로는 12.3 이 저장된다. scaling_factor : 100 으로 설정했으면 12.34 가 저장된다.
"coerce": true로 인해 “4.5” 가 integer 필드에 정상적으로 저장 되어도 _source 의 값은 그대로 “4.5” 이지만 검색 또는 집계는 4로 적용된다. null_value 옵션도 마찬가지로 _source 에는 해당 필드가 null 또는 존재하지 않는 것으로 표시되지만 검색, 또는 집계에는 null_value에 해당하는 값으로 적용이 된다. 전처리된 데이터가 아니면 항상 _source의 값은 변경되지 않는다.
사용 예
PUT my_number
{
"mappings": {
"properties": {
"number_val" : {
"type": "byte",
"coerce" : true
}
}
}
}
PUT my_number/_bulk
{ "index" : { "_id": "1" }}
{ "number_val": 3 }
{ "index" : { "_id": "2" }}
{ "number_val": 4.5 }
{ "index" : { "_id": "3" }}
{ "number_val": "5.2" }
GET my_number/_search
{
"query": {
"range": {
"number_val": {
"gte": 3,
"lt": 4.2
}
}
}
}
range 쿼리를 이용해서 3 보다 크거나 같고 4.2 보다 작은 값을 검색하면 4.5 값을 가진 "_id": "2" 도큐먼트가 같이 검색된다. 그 이유는 _source 에는 4.5 로 값이 들어가 있지만 number_val 필드는 byte 이기 때문에 실제로는 4.5 가 아닌 4 가 저장이 되어 있기 때문이다.
날짜 타입
날짜 타입은 ISO8601 형식을 따라 입력을 하고 일반적으로 다음과 같은 형태로 입력된 경우 자동으로 날짜 타입으로 인식이 된다.
- “2019-06-12”
- “2019-06-12T17:13:40”
- “2019-06-12T17:13:40+09:00”
- “2019-06-12T17:13:40.428Z”
위와 같은 ISO8601 형식이 아니라 “2019/06/12 12:10:30” 와 같이 입력하면 보통은 text, keyword 로 된다. 이 외에도 1550282065513 와 같이 long 타입의 정수인 epoch_millis 형태의 입력도 가능한데 epoch_millis 는 1970-01-01 00:00:00 부터의 시간을 밀리초 단위로 카운트 한 값이다. 필드가 date 형으로 정의 된 이후에는 long 타입의 정수를 입력하면 날짜 형태로 저장이 가능하다. “2019/06/10 12:10:30” 같은 형식으로 날짜를 저장하려면 format 옵션을 사용해서 형태를 지정해야 한다.
"format" : "<문자열 || 문자열 ...>" 입력 가능한 날짜 형식을 |
로 구분해서 지정한다. |
사용 예
PUT my_date
{
"mappings": {
"properties": {
"date_val": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy/MM/dd||epoch_millis"
}
}
}
}
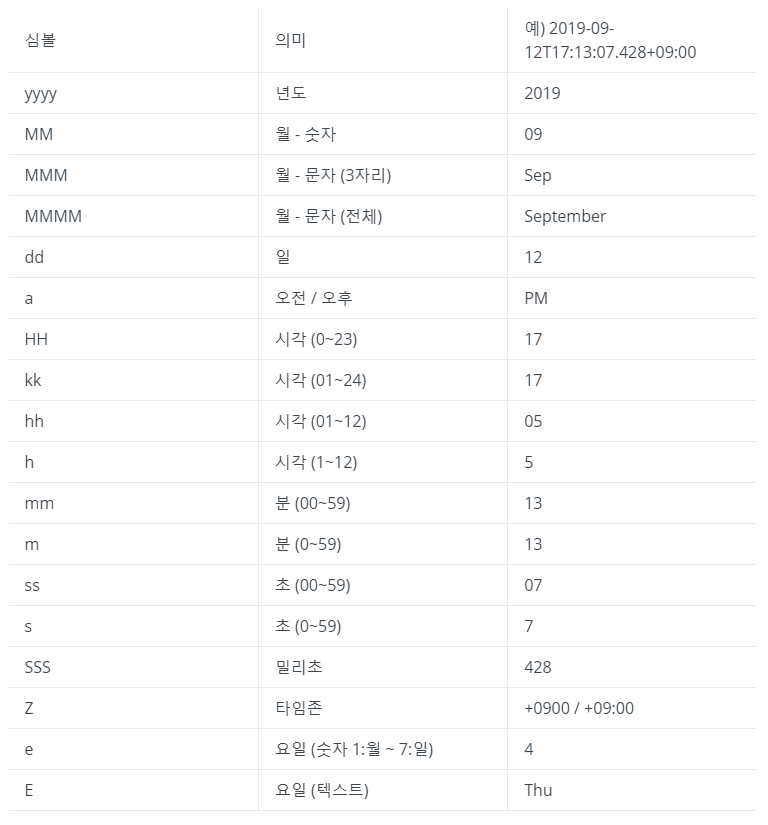
format은 공식 도큐먼트에서 확인할 수 있고, joda 심볼 기호들은 아래와 같다.
boolean 타입
true 와 false 두가지 값을 갖는 필드 타입이며 선언은 "type": "boolean" 로 한다. "true" 와 같이 문자열로 입력이 되어도 true 로 해석이 되어 저장된다.
"null_value" : <숫자값> - 필드값이 입력되지 않거나 null 인 경우 해당 필드의 디폴트 값을 지정.
Object 타입
한 요소가 여러 하위 정보를 가지고 있는 경우 object 타입 형태로 사용한다. object 필드를 선언할 때 properties를 입력하고 하위 필드를 정의한다.
characters라는 object 필드를 선언하는 예
PUT movie
{
"mappings": {
"properties": {
"characters": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "byte"
},
"side": {
"type": "keyword"
}
}
}
}
}
}
object 필드를 쿼리로 검색 하거나 집계를 할 때는 다음과 같이 마침표 . 를 이용해서 하위 필드에 접근한다.
GET movie/_search
{
"query": {
"match": {
"characters.name": "Iron Man"
}
}
}
Elasticsearch에는 따로 배열(array) 타입의 필드를 선언하지 않으며 필드 타입의 값만 일치하면 다음과 같이 값을 배열로도 넣을 수 있다.
{ “title”: “Romeo and Juliet” }
{ “title”: [ “Romeo and Juliet”, “Hamlet” ] }
PUT movie/_doc/2
{
"title": "The Avengers",
"characters": [
{
"name": "Iron Man",
"side": "superhero"
},
{
"name": "Loki",
"side": "villain"
}
]
}
PUT movie/_doc/3
{
"title": "Avengers: Infinity War",
"characters": [
{
"name": "Loki",
"side": "superhero"
},
{
"name": "Thanos",
"side": "villain"
}
]
}
characters 필드의 name 값은 “Loki” 이고 side 값은 “villain” 인 도큐먼트를 검색하는 예
GET movie/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"characters.name": "Loki"
}
},
{
"match": {
"characters.side": "villain"
}
}
]
}
}
}
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0611372,
"hits" : [
{
"_index" : "movie",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0611372,
"_source" : {
"title" : "Avengers: Infinity War",
"characters" : [
{
"name" : "Loki",
"side" : "superhero"
},
{
"name" : "Thanos",
"side" : "villain"
}
]
}
},
{
"_index" : "movie",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.9827781,
"_source" : {
"title" : "The Avengers",
"characters" : [
{
"name" : "Iron Man",
"side" : "superhero"
},
{
"name" : "Loki",
"side" : "villain"
}
]
}
}
]
}
}
{"name": "Loki", "side": "villain"} 값을 포함하고 있는 도큐먼트는 "_id" : "2" 하나 뿐인데 검색 결과는 "_id" : "3" 을 포함하고 있다. 그 이유는 역색인을 할 때 필드 별로 생성되기 때문이다.

Nested 타입
object 타입 필드에 있는 여러 개의 object 값들이 서로 다른 역 색인 구조를 갖도록 하려면 nested 타입으로 지정해야 한다.
PUT movie
{
"mappings": {
"properties": {
"characters": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"side": {
"type": "keyword"
}
}
}
}
}
}
위쪽 object 예제와 동일하게 데이터를 입력하고 {"name": "Loki", "side": "villain"} 를 검색해보면 검색 결과가 하나도 나타나지 않는다. nested 필드를 검색 할 때는 반드시 nested 쿼리를 써야 한다. path라는 옵션으로 nested로 정의된 필드를 먼저 명시해야 한다.
GET movie/_search
{
"query": {
"nested": {
"path": "characters",
"query": {
"bool": {
"must": [
{
"match": {
"characters.name": "Loki"
}
},
{
"match": {
"characters.side": "villain"
}
}
]
}
}
}
}
}
결과로 {"name" : "Loki", "side" : "villain"} 값을 포함하고 있는 "_id" : "2" 도큐먼트만 검색이 된다. nested 쿼리로 검색하면 nested 필드의 내부에 있는 값 들을 모두 별개의 도큐먼트로 취급한다.
위치 정보 - Geo
위치 정보를 표시하거나 검색하기 위해 위치 정보를 저장할 수 있는 타입이다.
Geo Point
Geo Point 는 지도 위의 한 점을 나타내는 값인 위도(latitude)와 경도(longitude) 두 개의 실수 값을 가지는 타입이다.
Geo Point 필드는 매핑에서 다음과 같이 "type": "geo_point" 로 선언한다.
PUT my_geo
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
Geo Point 필드의 경우는 반드시 데이터를 입력하기 전에 인덱스 매핑을 정의 해 주어야 한다. 그렇지 않으면 float 타입으로 데이터가 생성된다.
PUT my_geo/_doc/1
{
"location": {
"lat": 41.12,
"lon": -71.34
}
}
위경도 값인 geohash 는 전 세계 지도를 바둑판 모양의 격자로 나누어 각 칸 마다 숫자와 알파벳으로 기호를 메기고, 그 칸을 다시 나누어 다시 기호를 추가하는 방식으로 표현한 것이다. 자릿수가 커질수록 정밀도가 높아지며 보통 1자리 값이면 대륙, 2자리 값이면 대한민국 영토 정도의 크기이고 4자리 값이면 대도시, 7자리 값이면 길거리 한 블록 정도의 정밀도를 나타낸다.
geo_point 값의 검색에 주로 사용 되는 것은 geo_bounding_box 쿼리와 geo_distance 쿼리가 있다.
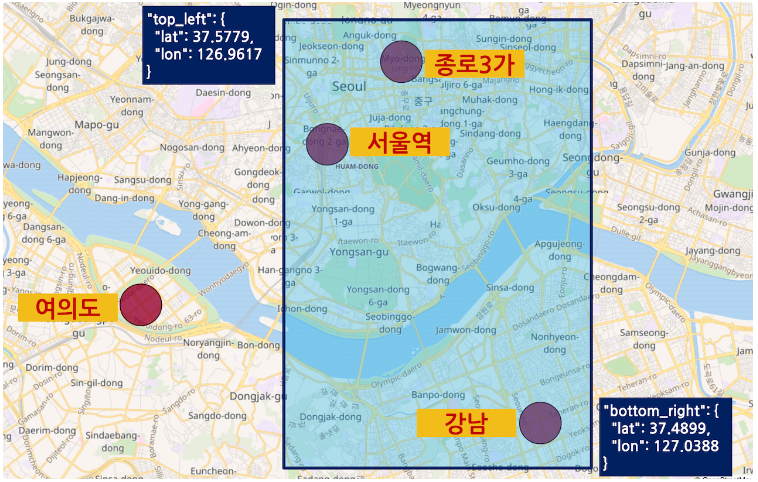
geo_bounding_box 쿼리
geo_bounding_box 쿼리는 top_left 와 bottom_right 두 개의 옵션에 각각 위치점을 입력하고 이 점들을 토대로 그린 네모 칸 안에 위치하는 도큐먼트들을 불러오는 쿼리이다.
GET my_geo/_search
{
"query": {
"geo_bounding_box": {
"location": {
"bottom_right": {
"lat": 37.4899,
"lon": 127.0388
},
"top_left": {
"lat": 37.5779,
"lon": 126.9617
}
}
}
}
}
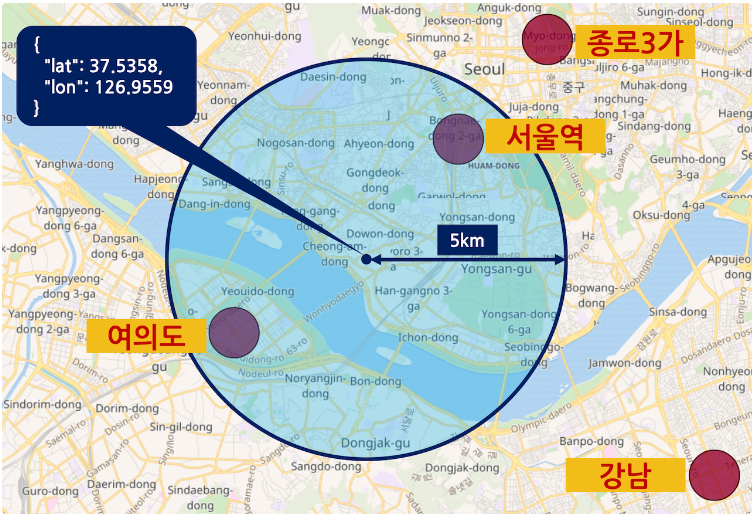
geo_distance 쿼리
geo_distance 쿼리는 하나의 위치점을 찍고 distance 옵션을 이용해서 입력한 반경의 원 안에 있는 도큐먼트들을 불러오는 쿼리이다.
GET my_geo/_search
{
"query": {
"geo_distance": {
"distance": "5km",
"location": {
"lat": 37.5358,
"lon": 126.9559
}
}
}
}
Geo Shape
Geo Shape 은 선, 면 등의 2차원 값을 저장하고 쿼리할 수 있다.
Geo Shape 필드는 "type": "geo_shape" 으로 선언한다.
PUT my_shape
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}
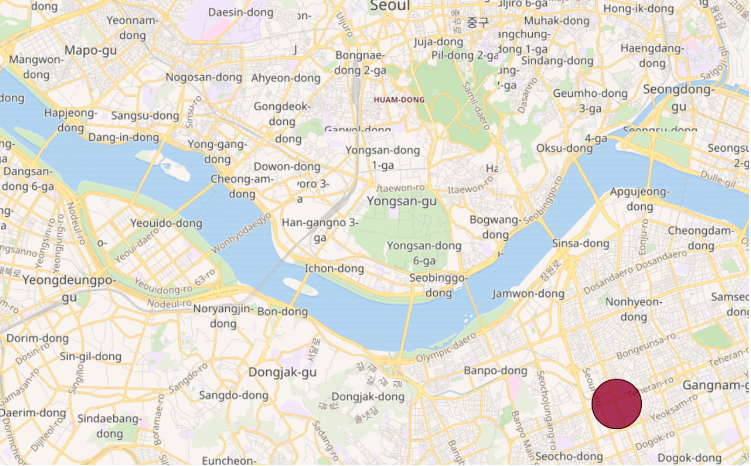
도큐먼트에도 점, 선, 다중점, 다중선, 다각형 등을 "type" 값에 각각 다음과 같이 지정하고 "coordinates" 값에 위치 정보를 [ -71.34, 41.12 ] 같이 [경도, 위도] 의 순서로 배열 형식으로 입력한다.
PUT my_shape/_doc/1
{
"location": {
"type": "point",
"coordinates": [
127.027926,
37.497175
]
}
}
"type": "multipoint" - 여러 점을 하나의 값으로 저장합니다. 점들을 배열로 입력합니다.
PUT my_shape/_doc/2
{
"location": {
"type": "multipoint",
"coordinates": [
[ 127.027926, 37.497175 ],
[ 126.991806, 37.571607 ],
[ 126.924191, 37.521624 ],
[ 126.972559, 37.554648 ]
]
}
}
"type": "linestring" - 점 2개 값를 배열로 입력하여 두 점을 잇는 직선을 저장합니다. 비행 경로 등을 저장할때 유용합니다.
PUT my_shape/_doc/3
{
"location": {
"type": "linestring",
"coordinates": [
[ 127.027926, 37.497175 ],
[ 126.991806, 37.571607 ]
]
}
}
"type": "multilinestring" - 여러개의 직선을 배열로 입력하여 저장합니다.
PUT my_shape/_doc/4
{
"location": {
"type": "multilinestring",
"coordinates": [
[
[ 127.027926, 37.497175 ],
[ 126.991806, 37.571607 ]
],
[
[ 126.924191, 37.521624 ],
[ 126.972559, 37.554648 ]
]
]
}
}
"type": "polygon" - 다각형, 배열 마지막에는 반드시 처음과 같은 점이 입력되어야 한다.
PUT my_shape/_doc/5
{
"location": {
"type": "polygon",
"coordinates": [
[
[ 127.027926, 37.497175 ],
[ 126.991806, 37.571607 ],
[ 126.924191, 37.521624 ],
[ 126.972559, 37.554648 ],
[ 127.027926, 37.497175 ]
]
]
}
}
"type": "multipolygon" - 여러 개의 다각형을 배열로 저장한다.
PUT my_shape/_doc/6
{
"location": {
"type": "multipolygon",
"coordinates": [
[
[
[ 127.027926, 37.497175 ],
[ 126.991806, 37.571607 ],
[ 126.924191, 37.521624 ],
[ 127.004943, 37.504810 ],
[ 127.027926, 37.497175 ]
]
],
[
[
[ 126.936893, 37.555134 ],
[ 126.967894, 37.529170 ],
[ 126.924191, 37.521624 ],
[ 126.936893, 37.555134 ]
]
]
]
}
}
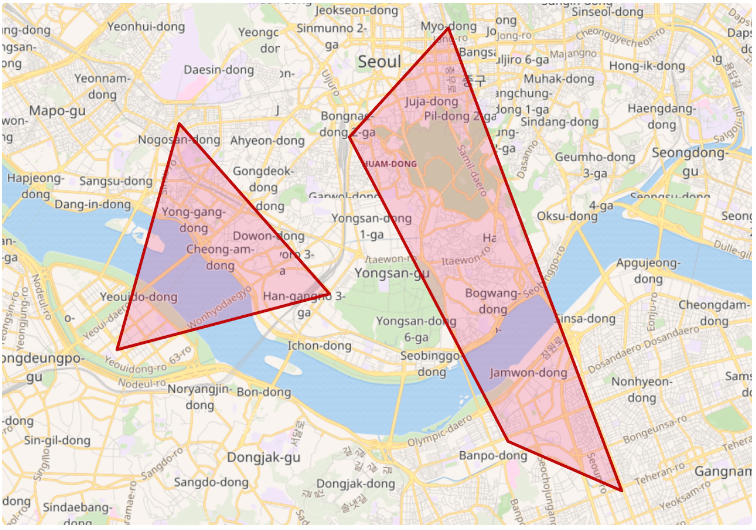
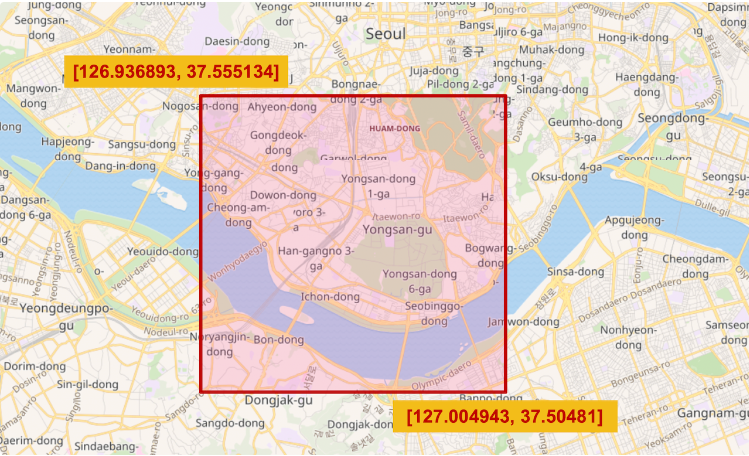
"type": "envelope" - 바른 각도의 직사각형 영역을 저장할때는 polygon 으로 4개의 점을 입력하여 지정할 수도 있지만, 대신 envelope 을 사용하면 좌측 상단(upper left) 와 우측 하단(lower right) 점 두개만 이용해서 그리는 것도 가능하다
PUT my_shape/_doc/7
{
"location": {
"type": "envelope",
"coordinates": [
[ 126.936893, 37.555134 ],
[ 127.004943, 37.50481 ]
]
}
}
geo_shape 쿼리
Geo Shape 타입의 값들을 검색하려면 geo_shape 쿼리를 사용해야 한다.
입력해야하는 옵션으로는
"shape": { } 에 검색할 영역의 "type" 과 "coordinates" 값을 입력하고,
"relation" 에 검색할 영역과 검색되는 도큐먼트가 겹치거나 포함되는 관계 조건 값을 입력한다.
relation 옵션에 입력 가능한 값은 intersects, disjoint, within 3가지가 있다.
"relation": "intersects" - 디폴트 값입니다. 쿼리 영역과 도큐먼트 값 영역이 일부라도 겹쳐지면 참.
"relation": "disjoint" - 도큐먼트 값 영역이 쿼리 영역과 겹치지 않는 쿼리 영역 바깥에 있는 도큐먼트들을 가져온다.
"relation": "within" - 도큐먼트의 값들이 모두 쿼리 영역 안에 완전히 포함 되어 있는 도큐먼트들을 가져온다.
PUT my_shape/_doc/1
{
"place": "경복궁",
"location": {
"type": "envelope",
"coordinates": [
[ 126.9735, 37.5837 ],
[ 126.9802, 37.5756 ]
]
}
}
PUT my_shape/_doc/2
{
"place": "명동",
"location": {
"type": "envelope",
"coordinates": [
[ 126.9778, 37.5656 ],
[ 126.9884, 37.5558 ]
]
}
}
PUT my_shape/_doc/3
{
"place": "홍대",
"location": {
"type": "envelope",
"coordinates": [
[ 126.9199, 37.5583 ],
[ 126.9347, 37.5481 ]
]
}
}
geo_shape 쿼리를 이용해서 “top_left”: {“lat”: 37.5800, “lon”: 126.9687}, “bottom_right”: {“lat”: 37.5543, “lon”: 126.9900} 의 직사각형 (envelope) 범위 안에 있는 도큐먼트 들을 relation 별로 검색
GET my_shape/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[ 126.9687, 37.58 ],
[ 126.99, 37.5543 ]
]
},
"relation": "intersects"
}
}
}
}
결과: 경북궁 , 명동
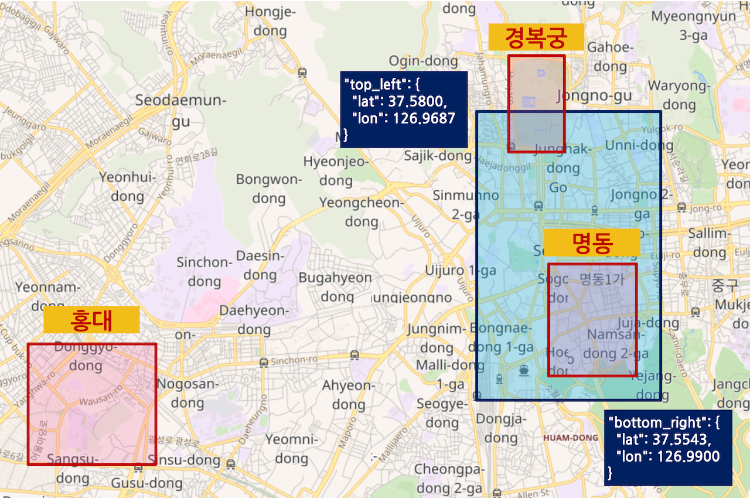
"relation": "intersects" - 쿼리 영역에 조금이라도 걸쳐 있는 "place" : "경복궁" 과 "place" : "명동" 도큐먼트들이 결과로 나온다.
GET my_shape/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[ 126.9687, 37.58 ],
[ 126.99, 37.5543 ]
]
},
"relation": "within"
}
}
}
}
"relation": "within" - 쿼리 영역에 완전히 포함되어 있는 "place" : "명동" 도큐먼트만 결과로 나온다.
GET my_shape/_search
{
"query": {
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[ 126.9687, 37.58 ],
[ 126.99, 37.5543 ]
]
},
"relation": "disjoint"
}
}
}
}
"relation": "disjoint" - 쿼리 영역 바깥에 있는 "place" : "홍대" 도큐먼트가 결과로 나온다.
기타 필드 타입 - IP, Range, Binary
생략.
멀티 필드 (Multi Field)
도큐먼트에는 하나의 필드값만 있지만 이 필드의 값을 여러 개의 역 색인 및 doc_values 들로 저장할 수 있는 다중 필드, 즉 멀티 필드 기능이 있다. 매핑에서 필드명 아래에 "fields" : { } 항목에서 다시 새로운 필드를 정의하고 설정한다.
PUT my_index
{
"mappings": {
"properties": {
"<필드명1>": {
"type": "text",
"fields": {
"<필드명2>": {
"type": "<타입>"
}
}
}
}
}
}
보통은 text 타입 아래에 keyword 타입을 같이 정의하기 위해서 사용되며 다이나믹 매핑으로 문자열 값이 입력되면 자동으로 이런 모양으로 생성된다. 이 외에도 하나의 텍스트 필드에 여러 개의 애널라이저를 적용하기 위해서도 사용할 수 있다.
다음은 my_index 인덱스의 message 필드에 서로 다른 애널라이저들을 사용하는 english, nori 멀티 필드를 정의하는 예제
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"nori_analyzer": {
"tokenizer": "nori_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"message": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
},
"nori": {
"type": "text",
"analyzer": "nori_analyzer"
}
}
}
}
}
}
nori_analyzer 는 기본적으로 제공되는 애널라이저가 아니기 때문에
"settings" : { }에서 만들어 줘야 한다.
message 필드값만 있어도 message, message.english, message.nori 총 3개의 역 색인이 생성되고, 위의 인덱스에 { "message": "My favorite 슈퍼영웅 is Iron Man" } 이라는 값을 입력하면 다음과 같이 3개의 역 색인이 생성된다.
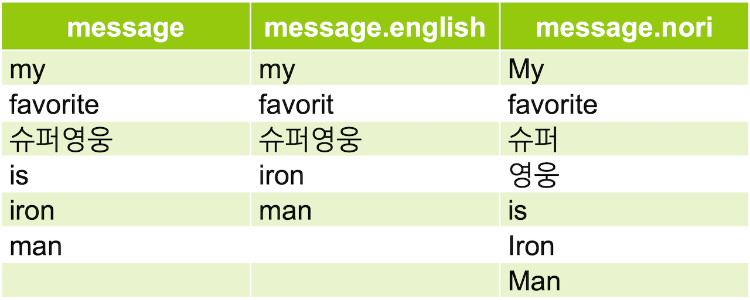
집계 - Aggregation
애그리게이션(Aggregation)에는 Metrics와 Bucket 두 종류가 있다.
테스트 데이터
PUT my_stations/_bulk
{"index": {"_id": "1"}}
{"date": "2019-06-01", "line": "1호선", "station": "종각", "passangers": 2314}
{"index": {"_id": "2"}}
{"date": "2019-06-01", "line": "2호선", "station": "강남", "passangers": 5412}
{"index": {"_id": "3"}}
{"date": "2019-07-10", "line": "2호선", "station": "강남", "passangers": 6221}
{"index": {"_id": "4"}}
{"date": "2019-07-15", "line": "2호선", "station": "강남", "passangers": 6478}
{"index": {"_id": "5"}}
{"date": "2019-08-07", "line": "2호선", "station": "강남", "passangers": 5821}
{"index": {"_id": "6"}}
{"date": "2019-08-18", "line": "2호선", "station": "강남", "passangers": 5724}
{"index": {"_id": "7"}}
{"date": "2019-09-02", "line": "2호선", "station": "신촌", "passangers": 3912}
{"index": {"_id": "8"}}
{"date": "2019-09-11", "line": "3호선", "station": "양재", "passangers": 4121}
{"index": {"_id": "9"}}
{"date": "2019-09-20", "line": "3호선", "station": "홍제", "passangers": 1021}
{"index": {"_id": "10"}}
{"date": "2019-10-01", "line": "3호선", "station": "불광", "passangers": 971}
Metrics
숫자 또는 날짜 필드의 값을 가지고 계산하는 집계하는 방식.
min, max, sum, avg
가장 흔하게 사용되는 aggregation
GET my_stations/_search
{
"size": 0,
"aggs": {
"all_passangers": {
"sum": {
"field": "passangers"
}
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"all_passangers" : {
"value" : 41995.0
}
}
}
aggregations 만 사용하는 경우에는 "size": 0 을 지정 하면 “hits”: [ ] 에 불필요한 도큐먼트가 검색되지 않아 쿼리 성능이 좋아진다.
GET my_stations/_search
{
"query": {
"match": {
"station": "강남"
}
},
"size": 0,
"aggs": {
"gangnam_passangers": {
"sum": {
"field": "passangers"
}
}
}
}
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"gangnam_passangers" : {
"value" : 29656.0
}
}
}
stats
min, max, sum, avg 값을 모두 가져와야 한다면 다음과 같이 stats aggregation을 사용하면 위 4개의 값 모두와 count 값을 한번에 가져온다.
GET my_stations/_search
{
"size": 0,
"aggs": {
"passangers_stats": {
"stats": {
"field": "passangers"
}
}
}
}
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"passangers_stats" : {
"count" : 10,
"min" : 971.0,
"max" : 6478.0,
"avg" : 4199.5,
"sum" : 41995.0
}
}
}
cardinality
필드의 값이 모두 몇 종류인지 분포값을 구할수 있다.
text 필드에서는 사용할 수 없으며 숫자 필드나 keyword, ip 필드 등에 사용이 가능하다.
사용자 접속 로그에서 IP 주소 필드를 가지고 실제로 접속한 사용자가 몇명인지 파악하는 등의 용도로 주로 사용된다.
GET my_stations/_search
{
"size": 0,
"aggs": {
"uniq_lines ": {
"cardinality": {
"field": "line.keyword"
}
}
}
}
{
"took" : 15,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"uniq_lines " : {
"value" : 3
}
}
}
percentiles
값들의 백분율 구한다. percents 옵션을 지정하지 않으면 기본값으로 1, 5, 25, 50, 75, 95, 99% 구간에 위치해 있는 값들을 표시해준다.
GET my_stations/_search
{
"size": 0,
"aggs": {
"pass_percentiles": {
"percentiles": {
"field": "passangers"
}
}
}
}
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"pass_percentiles" : {
"values" : {
"1.0" : 971.0000000000001,
"5.0" : 971.0,
"25.0" : 2314.0,
"50.0" : 4766.5,
"75.0" : 5821.0,
"95.0" : 6478.0,
"99.0" : 6478.0
}
}
}
}
GET my_stations/_search
{
"size": 0,
"aggs": {
"pass_percentiles": {
"percentiles": {
"field": "passangers",
"percents": [ 20, 60, 80 ]
}
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"pass_percentiles" : {
"values" : {
"20.0" : 1667.5,
"60.0" : 5568.0,
"80.0" : 6021.0
}
}
}
}
percentile_ranks
값들을 입력하면 해당 값들의 백분율을 표시해준다.
GET my_stations/_search
{
"size": 0,
"aggs": {
"pass_percentile_ranks": {
"percentile_ranks": {
"field": "passangers",
"values": [ 1000, 3000, 6000 ]
}
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"pass_percentile_ranks" : {
"values" : {
"1000.0" : 10.059568131049886,
"3000.0" : 29.218263576617087,
"6000.0" : 79.1549295774648
}
}
}
}
Bucket
범위나 keyword 값 등을 가지고 도큐먼트를 집계하는 방식.
주어진 조건으로 분류된 버킷 들을 만들고, 각 버킷에 소속되는 도큐먼트들을 모아 그룹으로 구분한다.
각 버킷 별로 포함되는 도큐먼트의 개수는 doc_count 값에 기본적으로 표시가 되며 각 버킷 안에 metrics aggregation 을 이용해서 다른 계산들도 가능하다.
주로 사용되는 bucket aggregation 들은 Range, Histogram, Terms 등이 있다.
range
숫자 필드 값으로 범위를 지정하고 각 범위에 해당하는 버킷을 만드는 aggregation.
passangers 값이 각각 1000 미만, 1000~4000 사이, 4000 이상 인 버킷들을 생성하는 예제
GET my_stations/_search
{
"size": 0,
"aggs": {
"passangers_range": {
"range": {
"field": "passangers",
"ranges": [
{
"to": 1000
},
{
"from": 1000,
"to": 4000
},
{
"from": 4000
}
]
}
}
}
}
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"passangers_range" : {
"buckets" : [
{
"key" : "*-1000.0",
"to" : 1000.0,
"doc_count" : 1
},
{
"key" : "1000.0-4000.0",
"from" : 1000.0,
"to" : 4000.0,
"doc_count" : 3
},
{
"key" : "4000.0-*",
"from" : 4000.0,
"doc_count" : 6
}
]
}
}
}
aggs 에 설정한 from 은 이상 즉 버킷에 포함이고 to 는 미만 으로 버킷에 포함하지 않는다. 예를 들어 필드 값이 200 인 도큐먼트는 "key" : "100-200" 버킷에는 포함되지 않고 "key" : "200-300" 버킷에는 포함된다.
histogram: range 와 마찬가지로 숫자 필드의 범위를 나누는 aggs이다.
range는 from ~ to를 이용해서 각 버킷의 범위를 지정하는 반면 histogram은 interval 옵션을 이용해서 주어진 가격으로 버킷을 구한다.
range
from ~ to
0 ~ 2000
2000 ~ 4000
4000 ~ 6000
…
이런씩으로 2000 단위로 버킷을 구해야 될때는 histogram interval: 2000으로 지정하면 된다.
GET my_stations/_search
{
"size": 0,
"aggs": {
"passangers_his": {
"histogram": {
"field": "passangers",
"interval": 2000
}
}
}
}
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"passangers_his" : {
"buckets" : [
{
"key" : 0.0,
"doc_count" : 2
},
{
"key" : 2000.0,
"doc_count" : 2
},
{
"key" : 4000.0,
"doc_count" : 4
},
{
"key" : 6000.0,
"doc_count" : 2
}
]
}
}
}
range와 마찬가지로 key: 0.0은 0이상 2000미만을 의미하고, key 2000.0은 2000 이상 4000 미만을 의미한다.
date_range
날짜 필드를 범위 별 버킷으로 생성한다.
GET my_stations/_search
{
"size": 0,
"aggs": {
"date_his": {
"date_histogram": {
"field": "date",
"interval": "month"
}
}
}
}
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"date_his" : {
"buckets" : [
{
"key_as_string" : "2019-06-01T00:00:00.000Z",
"key" : 1559347200000,
"doc_count" : 2
},
{
"key_as_string" : "2019-07-01T00:00:00.000Z",
"key" : 1561939200000,
"doc_count" : 2
},
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 3
},
{
"key_as_string" : "2019-10-01T00:00:00.000Z",
"key" : 1569888000000,
"doc_count" : 1
}
]
}
}
}
date_histogram
날짜 필드를 interval 단위로 범위 버킷을 구한다.
GET my_stations/_search
{
"size": 0,
"aggs": {
"date_his": {
"date_histogram": {
"field": "date",
"interval": "month"
}
}
}
}
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"date_his" : {
"buckets" : [
{
"key_as_string" : "2019-06-01T00:00:00.000Z",
"key" : 1559347200000,
"doc_count" : 2
},
{
"key_as_string" : "2019-07-01T00:00:00.000Z",
"key" : 1561939200000,
"doc_count" : 2
},
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 3
},
{
"key_as_string" : "2019-10-01T00:00:00.000Z",
"key" : 1569888000000,
"doc_count" : 1
}
]
}
}
}
7.2 버전 부터는 interval 옵션이 사용 종료 권장(depricated) 되고 대신 fixed_interval 과 calendar_interval 으로 나누어 지게 되었다.. year, quarter, month, week, 같은 달력 기준의 값은
"calendar_interval" : "month"로 입력을 하고, 30일 처럼 정확히 구분되는 날짜들은"fixed_interval" : "30d"로 지정을 해야 한다.
terms
keyword 필드의 문자열 별로 버킷을 나누어 집계한다.
GET my_stations/_search
{
"size": 0,
"aggs": {
"stations": {
"terms": {
"field": "station.keyword"
}
}
}
}
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"stations" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "강남",
"doc_count" : 5
},
{
"key" : "불광",
"doc_count" : 1
},
{
"key" : "신촌",
"doc_count" : 1
},
{
"key" : "양재",
"doc_count" : 1
},
{
"key" : "종각",
"doc_count" : 1
},
{
"key" : "홍제",
"doc_count" : 1
}
]
}
}
}
terms aggregation 에는 field 외에도 가져올 버킷의 개수를 지정하는 size 옵션이 있으며 디폴트 값은 10 이다..
인덱스의 특정 keyword 필드에 있는 모든 값들을 종류별로 버킷을 만들면 가져와야 할 결과가 매우 많기 때문에 먼저 도큐먼트 개수 또는 주어진 metrics 연산 결과가 가장 많은 버킷 들을 샤드별로 계산해서 상위 몇개의 버킷들만 coordinate 노드로 가져오고, 그것들을 취합해서 결과를 나타낸다. 이 과정은 검색의 query 그리고 fetch 과정과 유사하다.
서브 집계 (Sub Aggregations)
Bucket Aggregation 으로 만든 버킷들 내부에 다시 "aggs" : { } 를 선언해서 또다른 버킷을 만들거나 Metrics Aggregation 을 만들어 사용이 가능하다.
stations 버킷 별로 avg aggregation을 이용해서 passangers 필드의 평균값을 계산하는 avg_psg_per_st 을 생성하는 예제
GET my_stations/_search
{
"size": 0,
"aggs": {
"stations": {
"terms": {
"field": "station.keyword"
},
"aggs": {
"avg_psg_per_st": {
"avg": {
"field": "passangers"
}
}
}
}
}
}
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"stations" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "강남",
"doc_count" : 5,
"avg_psg_per_st" : {
"value" : 5931.2
}
},
{
"key" : "불광",
"doc_count" : 1,
"avg_psg_per_st" : {
"value" : 971.0
}
},
{
"key" : "신촌",
"doc_count" : 1,
"avg_psg_per_st" : {
"value" : 3912.0
}
},
{
"key" : "양재",
"doc_count" : 1,
"avg_psg_per_st" : {
"value" : 4121.0
}
},
{
"key" : "종각",
"doc_count" : 1,
"avg_psg_per_st" : {
"value" : 2314.0
}
},
{
"key" : "홍제",
"doc_count" : 1,
"avg_psg_per_st" : {
"value" : 1021.0
}
}
]
}
}
}
GET my_stations/_search
{
"size": 0,
"aggs": {
"lines": {
"terms": {
"field": "line.keyword"
},
"aggs": {
"stations_per_lines": {
"terms": {
"field": "station.keyword"
}
}
}
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"lines" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "2호선",
"doc_count" : 6,
"stations_per_lines" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "강남",
"doc_count" : 5
},
{
"key" : "신촌",
"doc_count" : 1
}
]
}
},
{
"key" : "3호선",
"doc_count" : 3,
"stations_per_lines" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "불광",
"doc_count" : 1
},
{
"key" : "양재",
"doc_count" : 1
},
{
"key" : "홍제",
"doc_count" : 1
}
]
}
},
{
"key" : "1호선",
"doc_count" : 1,
"stations_per_lines" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "종각",
"doc_count" : 1
}
]
}
}
]
}
}
}
하위 버킷이 깊어질수록 elasticsearch 가 하는 작업량과 메모리 소모량이 기하급수적으로 늘어나기 때문에 예상치 못한 오류를 발생 시킬수도 있기 때문에 2레벨의 깊이 이상의 버킷은 생성하지 않는 것이 좋다.
Pipeline Aggregations
pipeline 에는 다른 버킷의 결과들을 다시 연산하는 min_bucket, max_bucket, avg_bucket, sum_bucket, stats_bucket, 이동 평균을 구하는 moving_avg, 미분값을 구하는 derivative, 값의 누적 합을 구하는 cumulative_sum 등이 있다.
월별 / 합계 / 누적 합계 예제
GET my_stations/_search
{
"size": 0,
"aggs": {
"months": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"sum_psg": {
"sum": {
"field": "passangers"
}
},
"accum_sum_psg": {
"cumulative_sum": {
"buckets_path": "sum_psg"
}
}
}
}
}
}
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"months" : {
"buckets" : [
{
"key_as_string" : "2019-06-01T00:00:00.000Z",
"key" : 1559347200000,
"doc_count" : 2,
"sum_psg" : {
"value" : 7726.0
},
"accum_sum_psg" : {
"value" : 7726.0
}
},
{
"key_as_string" : "2019-07-01T00:00:00.000Z",
"key" : 1561939200000,
"doc_count" : 2,
"sum_psg" : {
"value" : 12699.0
},
"accum_sum_psg" : {
"value" : 20425.0
}
},
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2,
"sum_psg" : {
"value" : 11545.0
},
"accum_sum_psg" : {
"value" : 31970.0
}
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 3,
"sum_psg" : {
"value" : 9054.0
},
"accum_sum_psg" : {
"value" : 41024.0
}
},
{
"key_as_string" : "2019-10-01T00:00:00.000Z",
"key" : 1569888000000,
"doc_count" : 1,
"sum_psg" : {
"value" : 971.0
},
"accum_sum_psg" : {
"value" : 41995.0
}
}
]
}
}
}
월별 / 합계 / 총합계
GET my_stations/_search
{
"size": 0,
"aggs": {
"mon": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"sum_psg": {
"sum": {
"field": "passangers"
}
}
}
},
"bucket_sum_psg": {
"sum_bucket": {
"buckets_path": "mon>sum_psg"
}
}
}
}
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"mon" : {
"buckets" : [
{
"key_as_string" : "2019-06-01T00:00:00.000Z",
"key" : 1559347200000,
"doc_count" : 2,
"sum_psg" : {
"value" : 7726.0
}
},
{
"key_as_string" : "2019-07-01T00:00:00.000Z",
"key" : 1561939200000,
"doc_count" : 2,
"sum_psg" : {
"value" : 12699.0
}
},
{
"key_as_string" : "2019-08-01T00:00:00.000Z",
"key" : 1564617600000,
"doc_count" : 2,
"sum_psg" : {
"value" : 11545.0
}
},
{
"key_as_string" : "2019-09-01T00:00:00.000Z",
"key" : 1567296000000,
"doc_count" : 3,
"sum_psg" : {
"value" : 9054.0
}
},
{
"key_as_string" : "2019-10-01T00:00:00.000Z",
"key" : 1569888000000,
"doc_count" : 1,
"sum_psg" : {
"value" : 971.0
}
}
]
},
"bucket_sum_psg" : {
"value" : 41995.0
}
}
}
Script 사용
Elasticsearch에서는 Groovy, Javascript, Python, Painless 등의 스크립트 언어를 사용할 수 있다.
주로 Painless를 많이 사용하는데, Painless는 Elasticsearch에 특화된 내부 스크립팅 언어로, 다양한 기능을 지원하며 안전성과 성능이 좋은편이다.
Painless 장점
- 스크립트 실행 도중 오류나 예외를 안전하게 처리되도록 설계되어 있다.
- Java와 유사한 구문을 가지고 있어 익숙한 문법을 사용할 수 있다. (기본자료형, 배열, 객체, 반복문, 조건문 등)
- 컴파일 타임에 코드를 최적화하여 실행 시간을 최소화하고 스크립트 실행에 필요한 메모리 사용을 최적화 한다.
- 외부 자바 클래스나 파일에 액세스할 수 없도록 제한되어 있고, 스크립트 실행 권한을 관리하여 악의적인 코드의 실행을 방지한다.
Painless 단점
- I/O 연산과 외부 리소스 액세스를 할 수 없다.
- 커뮤니티나 문서가 부족하다.
- 일반적으로 빠른 속도로 실행되지만 안전성과 보안 매커니즘에 의해 다른 스크립트 언어보다 성능이 낮을 수 있다.
- 일반적으로 Java와 비슷한 문법이지만 완전히 다른 언어이기 때문에 어느정도 학습 곡선이 존재한다.
모델링
1) Parent-Child 모델링
엘라스틱서치가 제공하는 Join data type을 바탕으로 설계하는 방법입니다. 하나의 인덱스에서 Parent와 Child 도큐먼트 간에 Join type으로 Parent, Child를 구분하고 Parent와 Child 도큐먼트에서 같은 라우팅 ID를 키로 제공하여 같은 샤드(Shard)에 위치하게끔 설계합니다. 이 방식은 전체 도큐먼트에서 업데이트와 삭제가 빈번하고 1:N 관계의 구조일 때 고려해 볼 만합니다. 유의 사항으로는 라우팅 ID를 별도로 관리해야 하는 점, 기존 쿼리에 비해 내부 연산이 많아 쿼리 자체에 부하가 있는 점(has_parent·has_child Query) 및 집계(Aggregation) 일부 쿼리 기능에 대한 제약 등이 있습니다.
2) Nested 모델링
엘라스틱서치에서 Nested data type을 활용해 설계하는 방법입니다. 하나의 인덱스에서 Nested data type을 선언하고 오브젝트 속성들을 정의하여 연속(Array)하게 배치하는 방식입니다. 두 개 이상의 속성을 가진 오브젝트를 배열(Array) 구조로 표현해야 할 때 고려해 볼 수 있습니다. 다만 이 방식을 사용할 경우 쿼리(Query)·집계(Aggregation) 및 업데이트(Update) 시 유의해야 합니다. Nested Type은 내부적으로 Nested Object 별로 저장하기 때문에 Nested가 포함된 문서 하나를 저장할 때 실제 내부적으로는 Nested Array Size + 1만큼 저장하게 됩니다. 따라서 별도의 Nested Query를 작성해야 하고 업데이트 시 이러한 유의 사항을 고려해 디자인 해야 합니다.
3) Application Side Join 모델링
기본 키(Primary Key)를 기준으로 관계(Relation) 있는 엔티티(Entity)들을 서로 다른 도큐먼트에 배치하여 Application side에서 키를 기준으로 조인(Join)하여 처리하는 방식입니다. 이 모델링은 1:1 관계의 구조로 기존 쿼리와 집계(Aggregation)를 그대로 사용해야 할 때 고려해 볼 수 있습니다. 엘라스틱서치 쿼리를 그대로 사용 가능한 장점이 있으나 Application side에서 키 값을 기준으로 2회 이상 조회하여 가공해야 하므로 페이징 및 정렬(Sorting) 처리를 유의해야 합니다. 일반적으로 관계가 있는 단순 조회 목적일 때 고려해 볼 만한 방법입니다.
4) Denormalization 모델링
데이터 전체를 비정규화하여 인덱싱하는 방법으로 각 데이터의 중복을 허용하여 조인(Join)이 필요하지 않도록 합니다. 이 기법은 조인(Join) 연산 자체가 필요 없으며 쿼리 시점에서 최고의 성능을 낼 수 있다는 점 때문에 잘 활용하면 최고의 모델링이 될 수 있습니다. 다만 데이터 크기가 기하급수적으로 증가할 수 있는 구조이기 때문에 공통 필드의 변경이 잦거나 한정된 물리 서버로 구성해야 한다면 유의해서 사용해야 합니다.
References:
https://esbook.kimjmin.net/
https://www.elastic.co/guide/index.html
https://steady-coding.tistory.com/573
https://www.samsungsds.com/kr/insights/elastic_data_modeling.html
댓글남기기