Kafka 알아보기 및 설치
Kafka를 쓰는 이유
- 메시지 브로커를 이용하므로서 애플리케이션 간 의존도를 낮춘다.
- 높은 처리량 (High throughput): 메시지를 인메모리로 처리하기 때문에 latency가 적고 throughput이 크다.
- 고가용성(High Availability): Zookeeper 및 Kafka를 cluster로 구성할 수 있기 때문에 특정 서버의 장애가 발생하더라도 정상적으로 서비스 가능함.
- 확장성 (Scalability): Boker, Partition, Consumer Group을 쉽게 추가하여 확장할 수 있다.
- 파일 시스템에 저장되기 때문에 메시지 유실 위험이 적고, 에러 복구가 용이하다.
- 프로토콜이 다른 MQ에 비해서 간단하기 때문에 오버헤드가 적음
kafka 구성
-
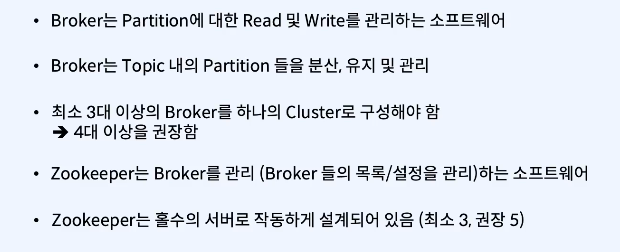
- 주키퍼(Zookeeper)
-
아파치에서 만든 Zookeeper는 Kafka의 메타데이터(metadata) 관리, 브로커의 정상상태 점검(health check), 노드 관리, 토픽 관리 등 코디네이터(조율자) 역할을 한다.
-
주키퍼는 변경사항에 대해 카프카에 알림 ex) 토픽을 생성하거나 제거, 브로커 추가하거나 제거
-
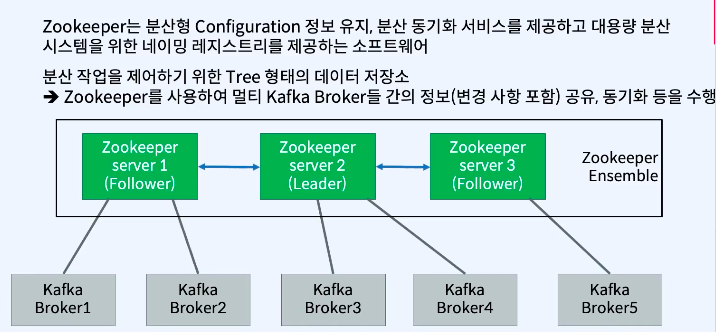
주키퍼는 여러 대의 서버를 앙상블(Ensemble,클러스터) 로 구성하고, 살아 있는 노드 수가 과반수 이상 유지 된다면 지속적인 서비스가 가능한 구조 -> 따라서 주키퍼는 반드시 홀수로 구성. (최소는 3대이상의 서버로, 큰 규모는 권장 5대)
가운데에 있는 2번 서버는 리더의 역할, 양쪽의 1,3은 팔로워 역할한다. 리더에서 데이터를 가져와서 동기화 하는 방식이다.
주키퍼는 분산형 configuration 정보들을 리더가 가지고 있고 팔로워들이 그 정보들을 복제해서 가지고 있는 형태이다.
분산 작업을 제어하기 위한 트리 형태의 데이터 저장소를 가지고 있다.
주키퍼가 3대 이상으로 이루어져 있는 형태를 주키퍼 앙상블(Zookeeper Ensemble)이라고 한다
-
kafka에서는 주키퍼에 대한 의존성을 제거 하기 위해 Apache Kafka 2.8 버전부터 주키퍼 대신 kraft 를 출시할 계획.

-
브로커(broker) : kafka가 설치된 메시지 브로커 서버
-
boker는 3대 이상 구축하는 것이 좋음.
-
Replication Factor:
- 브로커에게
리플리케이션 팩터 수 만큼 토픽안의 파티션들을 복제하도록 하는 설정 값 - 리더는 모든 데이터의 읽기 쓰기 작업을 처리히고, 팔로워는 리더를 주기적으로 보면서 자신에게 없는 데이터를 리더로부터 주기적으로 가져오는 방법으로 리플리케이션을 유지한다.
- replica.lag.time.max.ms 값 만큼 확인 요청이 오지 않는다면, 문제가 있는 팔로워를
ISR그룹에서 제거한다.
- 브로커에게
-
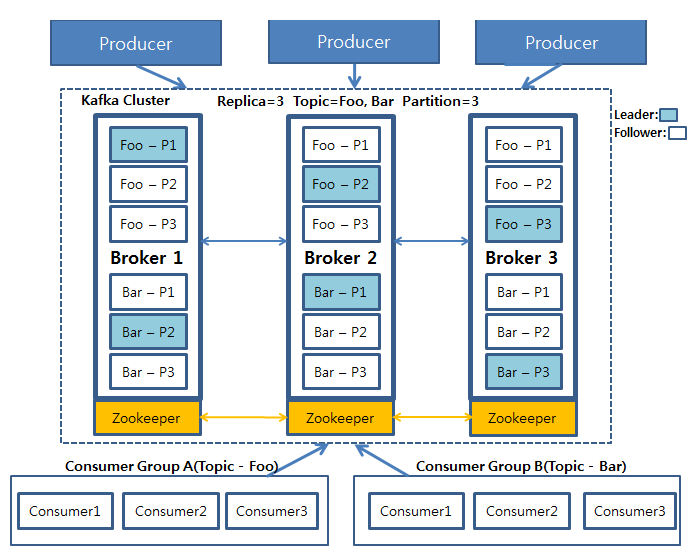
Producer(kafka-client)는 각 Topic의 Leader partition에 데이터를 전송
ack 값을 설정해서 데이터 복제에 대한 commit가능
0: leader partition에 데이터 전송하고 응답안받음 (보내는 사이에 데이터유실가능성 있음)1(기본값): leader partition에 데이터 전송하고 응답받음 (leader가 받고 follower들한테 복사하기전에 leader가 죽으면 데이터 유실가능성 있음)all: 모든 replica에 데이터 복제 후 응답받음(각 broker들한테서 응답받음, 데이터유실X, 속도느림)- all 설정시 모든 follower에 복제 성공을 기다리는 것은 아니고 kafka 설정에 min.insync.replicas(default: 1) 개수 만큼만 복제 성공을 확인한다.
- replica가 3일 때 min.insync.replicas=2 설정을 권장, 3 개중 하나의 브로커가 문제가 발생하여도 전체 장애로 이어지지 않기 때문.
-
-
토픽(topic) : kafka는 메시지 피드들을 토픽으로 구분하고, 각 Topic의 이름은 kafka 내에서 고유.
- 토픽은 여러개의 파티션으로 구성될 수 있음.
-
파티션(partition)


-
(파티션 하면) 분산 처리가 가능해지며, 파티션 수 만큼 컨슈머를 연결 가능
-
컨슈머가 파티션 내에 메시지를 읽은 위치를 나타내는 오프셋(offset)이 존재함.
-
Producer가 메시지를 생성하는 속도보다 Consumer 처리하는 속도가 늦어서 브로커에 메시지가 누적되면 장애가 발생할 수 있는데,
이때 Topic의 파티션 수를 늘이고 Consumer Group내의 Consumer 개수를 파티션 개수 만큼 늘여주면 메시지 처리 속도가 증가 함.
-
파티션수는 초기 생성 후 언제든지 늘릴 수 있지만, 반대로 한번 늘린 파티션 수는 줄일 수 없음. (토픽 삭제 후 다시 생성해야 됨) 적절한 파티션 수를 측정하기 어려운 경우에는 일단 적은 수(2~4개)의 파티션으로 운영해보고, 프로듀서 또는 컨슈머에서 병목현상이 발생하게 될때 조금씩 파티션 수와 프로듀서 또는 컨슈머를 늘려가는 방법으로 적정 파티션 수를 할당할 수 있다. 카프카에서는 브로커당 약 2,000개 정도의 최대 파티션 수를 권장하고 있기 때문에 과도한 파티션 수를 적용하기 보다는 목표 처리량에 맞게 적절한 파티션 수로 유지/운영하는 것이 권장
-
-
프로듀서(producer): kafka로 메세지를 보내는 역할을 하는 클라이언트
-
send() 메서드를 호출하면 Serializer가 내용을 serializing 한다.
-
Serializer는 Partitioner에게 해당 내용을 보낸다. Partitioner는 Key값을 확인하여 있다면, 해당 Topic에 Patition별로 보낼 준비를 한다. 없다면 Round Robin형식으로 Topic으로 알아서 할당할 준비를 한다.
-
압축옵션이 있다면 Compression을 진행한다.
-
Topic으로 Producer가 만들어준 Record를 전송한다. Batch처리가 있다면, 기준이되는 Batch.size와 Linger.ms 속성에 따라 처리한다.
-
Kafka는 메세지를 보낼 때 ACK 로직을 타게 돼는데 메세지의 량이 많아지게 돼면 메세지 처리 속도가 늦어져 Lag이 걸리는 latency가 발생한다.
이를 해결하기 위한 Producer의 방식은 Batch 처리를 이용한다. batch를 이용하면 메세지를 묶음 으로 보내기 때문에 replica처리 로직이 줄어들어 Latency를 방지 할 수 있다. 배치 관련 옵션은 batch.size와 linger.ms가 있다.
-
-
- 컨슈머(consumer)
-
kafka 토픽에서 한개의 메세지를 읽어오는 역할을 함.
-
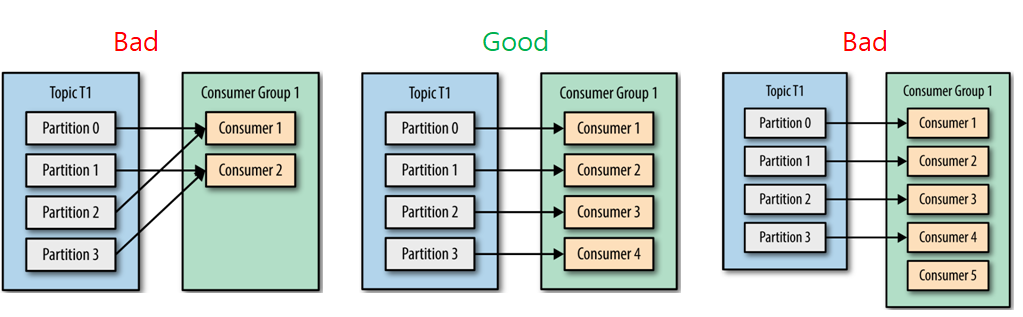
파티션 수 = 컨슈머 수 권장.
-
컨슈머 수가 파티션 수보다 많다면 더 많은 수의 컨슈머들은 그냥 대기 상태로 존재하기 때문에 더 빠르게 메세지를 가져오거나 처리량을 늘어나지 않음
-
컨슈머는 컨슈머 그룹 안에 속한 것이 일반적인 구조로, 하나의 컨슈머 그룹안에 여러 개의 컨슈머가 구성. 컨슈머는 토픽의 파티션과 1:1로 매핑 되어 메세지를 가져옴
-
하나의 파티션에 하나의 컨슈머만 붙을 수 있는 이유는
각각의 파티션에 대해서는 메세지 순서를 보장하기위해서다.
-
컨슈머 그룹(consumer group)
-
topic의 Partition과 Consumer그룹은 1:N매칭으로, 동일 그룹내 한개의 컨슈머만 연결가능.
-
여러 Consumer Group을 통해 병렬처리 가능
-
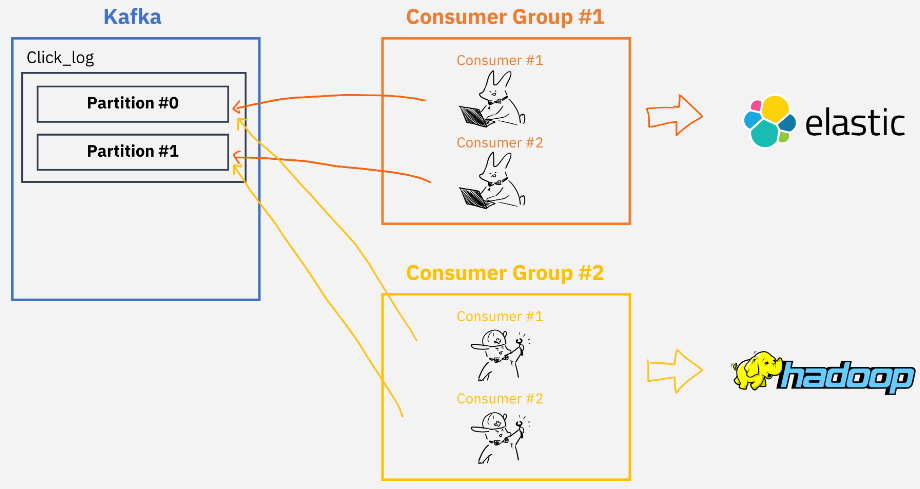
카프카는 일반 메시지 큐서비스들과 달리 컨슈머가 메시지를 가져가더라도 저장된 데이터를 삭제하지 않으며,
토픽에는 Consumer group별/토픽별로 offset을 나눠서 저장하기 때문에 Consumer group이 다르면 각자의 그룹은 서로 영향을 끼치지않음
-
-
세그먼트(segment) : 프로듀서가 전송한 실제 메세지가 브로커의 로컬 디스크에 저장되는 파일을 의미
-
메세지(message) 또는 레코드(record): 프로듀서가 브로커로 전송하거나 컨슈머가 읽어가는 데이터 조각.
- 오프셋(offset)
- 각 파티션마다 메세지가 저장되는 위치를
오프셋(offset)이라고 부르고, 오프셋은 파티션 내에서 유일하고 순사적으로 증가하는 숫자(64비트 정수) - 컨슈머가 오프셋을 확인하여 읽을 데이터를 파악하며, 읽은 후에는 커밋한다.
- 커밋은 consumer offset이라는 컨슈머가 읽은 위치를 저장하는 것이며, 커밋은 수동 커밋과 자동 커밋이 있다.
- 수동 커밋은 동기 오프셋 커밋(commitSync)와 비동기 오프셋 커밋(commitAsync)이 있다.
- 각 파티션마다 메세지가 저장되는 위치를
리밸런스
하나의 컨슈머 그룹 내에서 토픽에 대한 소유권을 재조정하는 과정.
-
리밸런스가 일어나는 조건
-
session.timeout.ms(default: 10초) 설정시간에 heartbeat 시그널을 받지 못하는 경우
-
max.poll.interval.ms(default: 5분) 설정시간에 poll() 메소드가 호출되지 않는 경우
- max.poll.records(default: 500)은 컨슈머의 poll()요청에 반환되는 최대 레코드 수, 가져온 다음 500개를 병렬로 처리하지 않고 순차 처리함.
-
session.timeout.ms와 max.poll.interval.ms 차이
- KIP-62는 폴링과 하트비트를 분리하여 두 개의 연속 폴 사이에 하트비트를 보낼 수 있습니다. 이제 두 개의 스레드(하트비트 스레드 및 처리 스레드) 가 실행 중이므로 KIP-62는 각각에 대한 시간 초과를 도입했습니다.
session.timeout.ms는 하트비트 스레드용이고 는max.poll.interval.ms처리 스레드용입니다.
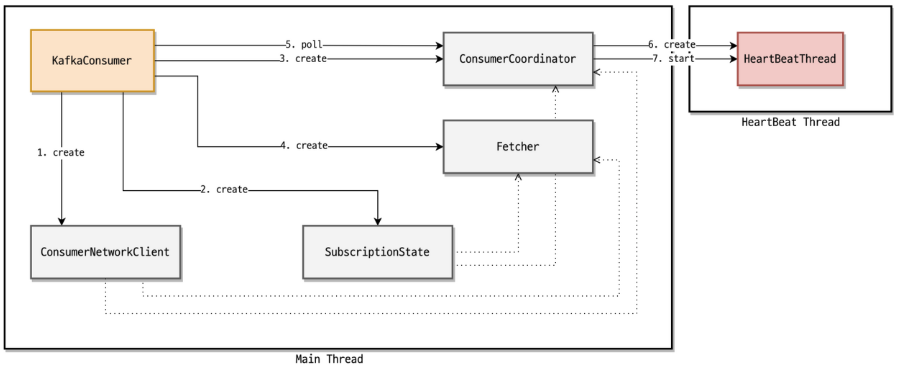
- KIP-62는 폴링과 하트비트를 분리하여 두 개의 연속 폴 사이에 하트비트를 보낼 수 있습니다. 이제 두 개의 스레드(하트비트 스레드 및 처리 스레드) 가 실행 중이므로 KIP-62는 각각에 대한 시간 초과를 도입했습니다.
-
-
리밸런스 발생 상황
-
컨슈머 그룹 내에 컨슈머를 추가 또는 제거.
-
파티션 추가.
-
네트워크 장애
-
Full GC가 오래 걸려 heartbeat 요청이 실패.
-
컨슈머가 메시지를 처리할 때 max.poll.interval.ms(예: 1분), max.poll.records(예: 60개 ) 인 상태일 때,
초당 1개를 처리하지 못하여 max.poll.interval.ms를 초과한 경우. (DB Query, 외부 API 등 요인으로)
-
-
리밸런스가 발생하면 일어나는 일들
- 그룹 코디네이터가 컨슈머 그룹 내의 모든 컨슈머들의 파티션 소유권을 박탈되면서 사용 불가 상태로 됨.
- 그룹 코디네이터가 가장 먼저 poll 요청을 보낸 컨슈머를 그룹리더로 지정하고, 리더에게 컨슈머 메타 데이터를 전송.
- 그룹 리더 컨슈머가 파티션의 소유권을 재조정하여 그룹 코디네이터에게 전달.
- rebalance.timeout.ms(default: 1분) 이내 poll 요청을 보내지 않은 컨슈머는 컨슈머 그룹에서 제외.
- 그렇다면 리밸런싱하는 시간은 rebalance.timeout.ms 시간 까지 증가할 수 있다는 의미이므로, 상황에 따라서 매우 큰 consumer-lag을 유발
- 그룹 코디네이터는 그룹 리더가 전달한 파티션의 소유권을 각 컨슈머에게 전달하고 리밸런싱 종료.
-
리밸런스 과정
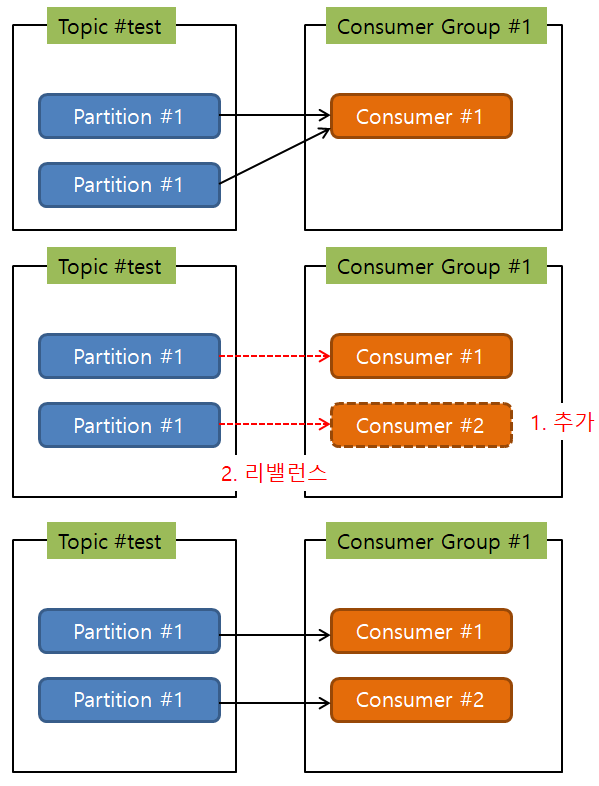
-
관련 옵션
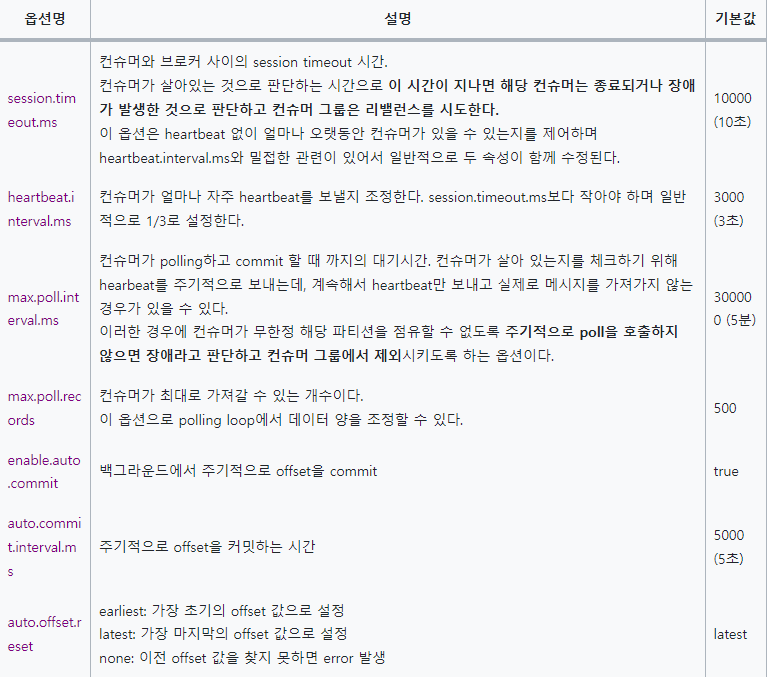
-
배포 시 리밸런싱
- Consumer Service를 배포하게 되면 종료 -> 시작 되므로 리밸런싱이 2번 일어남
- 만약 Consumer Service 3개가 Load Balancing되는 구조로 되어 있다면 rolling 배포 시 리밸런스는 6번 일어남
- Consumer Service가 종료 -> 시작 -> poll 요청하는 interval이 rebalance.timeout.ms(default: 1분)이 내이면 6번이지만, 시간을 초과하여 컨슈머그룹에서 제외되고, 추후 다시 join하게 되면 다시 리밸런스가 일어나므로 6번보다 많아진다.
- 해결 방법은?
- session.timeout.ms(default: 10초)를 배포 시간만큼 늘인다?
- 컨슈머 장애 시 늘인 시간만큼 리밸런스가 늦어지므로 브로커에 메시지가 많이 쌓일 수 있다.
- session.timeout.ms(default: 10초)를 배포 시간만큼 늘인다?
- 카프카 컨슈머 애플리케이션의 경우 MSA 구조로 따로 빼서 개발/배포하는 방식이 좋다고 한다.
- 블루/그린 배포
- 이전 버전의 애플리케이션 구성과 신규 버전 애플리케이션을 동시에 띄워 놓고 트래픽을 전환하는 방식으로, 신규 버전 애플리케이션들이 준비 되면 기존 애플리케이션을 모두 중단하여 리밸런싱을 한번만 발생하도록 할 수 있음.
- 서비 리소스 낭비가 있다.
- 롤링 배포
- 애플리케이션을 하나씩 배포하는 방식.
- 서비 리소스 낭비를 줄일 수 있다.
- 리밸런싱이 여러번 일어남.
- 카나리 배포
- 1개를 먼저 배포하여 문제가 없는지 확인한 다음 나머지 인스턴스에 배포하는 방식
- 나머지 인스턴스에 배포할 때 블루/그린 또는 롤링 배포.
카프카 멱등성
기본 프로듀서의 동작 방식은 적어도 한번 전달(at least once delivery)을 지원한다.
적어도 한번 전달이란, 프로듀서가 클러스터에 데이터를 전송하여 저장할 때 적어도 한번 이상 데이터를 적재할 수 있고 데이터가 유실되지 않음을 뜻한다. 두번 이상 적재되어 중복이 발생할 가능성은 있다.
멱등성 프로듀서는 기본 프로듀서와 달리 데이터를 브로커로 전달할때 프로듀서 PID(Producer unique ID)와 시퀀스 넘버(sequence number)를 함께 전달한다. 그러면 브로커는 프로듀서의 PID와 시퀀스 넘버를 확인하여 동일한 메시지의 적재 요청이 오더라도 단 한번만 데이터를 적재한다.
enable.idempotence 옵션 : 기본값은 false이고, true일 경우 멱등성 프로듀서로 동작하게된다.
‘true’로 설정하면 생산자는 각 메시지의 정확히 하나의 복사본이 스트림에 기록되도록 하고, ‘false’인 경우 브로커 오류 등으로 인해 생산자가 재시도하고 재시도된 메시지의 중복을 스트림에 쓸 수 있다. 멱등성을 활성화하려면 max.in.flight.requests.per.connection5보다 작거나 같아야 하고(허용되는 모든 값에 대해 메시지 순서가 유지됨) retries0보다 커야 하며 acks‘all’이어야 한다.
Producer의 멱등성은 위와 같이 설정하면 되지만 Consumer에서 offset을 갱신하기 전에 오류가 발생하면 중복이 발생할 수 있기 때문에 Consumer에서도 멱등성이 보장될 수 있도록 구현해야 한다. 그 외에도 중복 request로 event가 두번 발생할 수 도 있기 때문에 Consumer에서 중복을 막는 로직은 필수로 들어가야 한다. 중복을 막는 로직은 event id 또는 key 값이 처리되었는지 먼저 검증하고 이미 처리된 건이면 skip 후 offset을 commit하도록 하고, 처리되지 않은 건이면 처리 후 offset을 commit하도록 해야 한다. 이와 관련해서 Consumer의 enabled.auto.commit 속성은 false로 설정하고 수동으로 commit하도록 한다.
토픽명
- 길이는 249자 미만의 영어 대소문자, 숫자 0부터 9, 하이픈(-) 조합으로 생성하는 것을 권장
- 언더바(_), 마침표(.)는 사용 가능하지만 카프카 내부에서 사용하는 명칭과 겹치거나 오류가 발생할 수 있음.
Producer 오류 핸들링
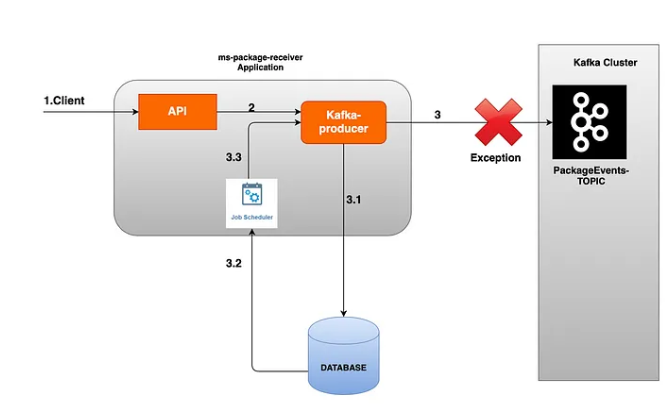
- 메시지를 발행할 때 다음과 같은 이유로 전송 실패 할 수 있다.
- Kafka 클러스터 다운
- “acks”가 “all”이고 min.insync.replicas에 지정된 수 만큼 복제가 실패한 경우
- 전송 타임 아웃
- 리더 다운으로 새 리더 선출 진행 중
- 브로커 메시지 크기 한도 초과
- 전송 크기 제한 초과
- 직렬화 실패
- 실패 핸들링 방법
- 방법 1: 새로운 큐에 실패 토픽을 발행: Kafka 클러스터가 다운될 수 있으므로 별도의 큐 브로커에 저장하고 별도 consumer로 처리.
- 방법 2: 실패 시 database에 event를 저장하고 별도 batch로 처리 ( 좀 더 안정적이고, 이벤트 복구 시점을 개발자가 정할 수 있음)
기타
-
kafka는 메시지의 순서를 보장하지 않기 때문에 메시지 순서를 보장해야되는 곳에서는 SQS나 RabbitMQ로 싱글 큐를 사용하는 것이 좋음.
-
config/server.properties의 log.dir 옵션에 정의한 디렉토리에 데이터가 저장됨. kafka는 페이지 캐시 를 사용하여 디스크 입출력 속도를 높여 처리 속도가 느리지 않음. 페이지 캐시란 OS에서 파일 입출력의 성능 향상을 위해 만들어 놓은 메모리 영역을 말하며, 브로커를 실행하는데 힙 메모리 사이즈를 크게 설정할 필요 없음.
-
외부 이벤트는 시스템간의 결합도를 줄이는 목적으로 설계한다.
-
외부 이벤트를 정의할 때 구독자의 행위를 고려하지 않는다
-
이벤트를 설계할 때 행위(event)와 상태(state)를 잘 구분지어서 설계해야 한다.
- 행위는 상태를 변경시킬 수도 있고 변경시키지 않을 수 있다.
-
식별자만 페이로드에 포함하는 zero payload 방식을 선택하지 않은 이유는 API 호출로 인한 물리적 결합도가 생기고 이에 대한 다양한 부가 기능이 추가되어야 한다.(fallback 전략 등)
-
이벤트가 누락되거나 밀렸을 경우 zero payload의 식별자를 통해 엔티티의 최신 상태를 조회했을 때 현재 다루는 이벤트의 목적과 다른 데이터를 소비할 수 있다.
-
full payload의 경우 이벤트 자체의 기록만으로 리플레이를 할 수 있다.
-
zero payload 방식에서 API를 통해 엔티티를 제공할 때 어차피 엔티티 자체에 불필요한 데이터가 담기거나 외부에 공개하고 싶지 않은 값들이 노출될 수 있다.
-
내부 서비스간의 소통에 full payload 방식을 사용한다면 이벤트 데이터의 컨버팅 과정을 생략할 수 있다. 전사적으로는 규약 없이 데이터를 흘릴 수 있기 때문이다. 하지만 사내망을 벗어나게 이런 이벤트를 흘려서는 안된다.
-
zero payload 방식 단점 : 만약 B라는 서비스가 Event를 발행하였고, A라는 서비스가 해당 Event를 Consumed 후 필요하여 API Call → 이때 B가 장애 상황이라면 A 역시 연쇄 장애 발생
- B라는 서비스는 트래픽이 많이 몰리지 않는 특성을 갖고 있어야 할 것 같다. 즉, 이벤트를 발행하는 주기가 빈번하지 않으며 혹여나 연쇄작용으로 A가 장애가 발생하더라도 다른 서비스에 영향을 주지 않는 서비스 간 결합도가 최소한으로 설계되어져 있어야 할 것이다.
-
배민 zero payload
가게에서 이벤트를 발행할 때, 메시지를 다 담아서 보내는 것이 아니라, 딱 가게 ID만 넣어서 보내는 것. 물론 몇가지 정보가 더 들어가기는 함.
이벤트가 발행되었으면, 이벤트를 수신하는 곳에서는, 이벤트안의 가게 ID를 보고, 이 가게의 데이터가 바뀌었구나 하고 위그림의 경우, 가게노출시스템과 가게 업주 시스템에서 서로 합의한 API를 호출한다. 그래서 해당 API의 데이터로 데이터를 채운다.
그러면 왜 변경된 데이터나, 전체 데이터를 채워서 보내지 않음?
-
변경된 데이터만 보내게 되면, 이벤트 순서를 고민해야함.
예를들어, 가게가 연락처를 A라했다가 B로 했다고하자. 그런데 이벤트는 B 다음에 A가 올 수도있다. 이 문제를 해결하려면 할 수는 있는데, 굉장히 많은 고민을 해야한다.
그래서 이걸 고민하지말자, 그냥 이벤트오면 이게 가장 최신이라고 보고, 항상 최신의 데이터를 갱신하자라고 결정.
-
변경된 데이터가 아니라 그냥 전체 데이터를 채워서 보내면 안되나?
각 시스템에서 원하는 데이터가 다 다르다. 가게노출에서 원하는 데이터랑, 광고 리스팅 시스템에서 원하는 데이터가 다르다. 동일 이벤트지만 다른 API를 만들어야한다.
그러면 그냥 모든 데이터 채워서 보내면 되지 않나? ➡ 테이블이 수십갠데 현실적이지 않다.
위의 두가지 문제 해결하기 위해서 딱 가게의 최소정보(거의 가게 ID만 보냄)만 넣어서 이벤트 발행하기로함.
나머지는 보통 common API를 만들어두고, specific한 API를 만든 다음에, 각 시스템들이 회신받은 이벤트면, 항상 API를 호출해서 최신의 데이터를 받아서 각 시스템들(앞단에 있는 시스템들)을 갱신하는 식으로 진행.
-
Local 컴퓨터에 테스트 용 설치
설치환경: Windows 10 Pro, WSL2 (Ubuntu)
docker-desktop 설치
-
Docker Desktop은 중소기업(직원 수 250명 미만, 연간 매출 1,000만 달러 미만), 개인 용도, 교육 및 비상업적 오픈 소스 프로젝트에 무료로 제공.
-
그렇지 않으면 전문적인 사용을 위해 유료 구독이 필요
-
https://docs.docker.com/desktop/install/windows-install/에서 Windows 용 도커 데스크톱을 다운로드 한다.
-
다운로드 받은 Docker Desktop Installer.exe를 실행하여 설치.
-
컴퓨터를 재시작합니다.
docker-compose 설치
-
docker-desktop은 window에 설치하였고, docker-compose 및 kafka는 wsl로 설치된 ubuntu에 설치.
-
install document: https://docs.docker.com/compose/install/other/
$ sudo curl -SL https://github.com/docker/compose/releases/download/v2.17.2/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose
$ sudo chmod +x /usr/local/bin/docker-compose
$ sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
$ docker-compose version [10:06:43]
Docker Compose version v2.17.2
docker-compose.yml 작성
-
document: https://github.com/wurstmeister/kafka-docker
https://github.com/wurstmeister/kafka-docker/blob/master/docker-compose-single-broker.yml
https://github.com/wurstmeister/kafka-docker/blob/master/docker-compose-swarm.yml
$ mkdir /docker-kafka
$ vim docker-compose.yml
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
container_name: kafka
ports:
- "9901:9901"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: INSIDE://:9092,OUTSIDE://192.168.164.68:9901
KAFKA_LISTENERS: INSIDE://:9092,OUTSIDE://0.0.0.0:9901
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
volumes:
- /var/run/docker.sock:/var/run/docker.sock
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "8080:8080"
restart: always
environment:
- KAFKA_CLUSTERS_0_NAME=local
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka:9092
- KAFKA_CLUSTERS_0_ZOOKEEPER=zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: INSIDE://:9092,OUTSIDE://[내컴퓨터 IP]:9901
docker-compose 실행
$ docker-compose -f /docker-kafka/docker-compose.yml up -d
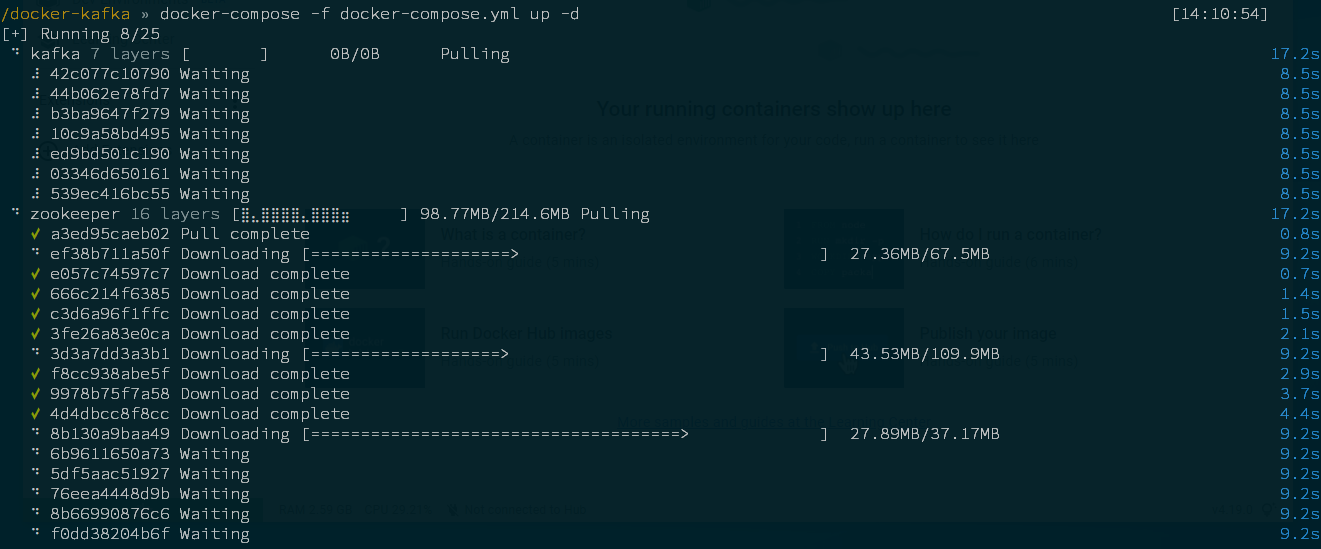
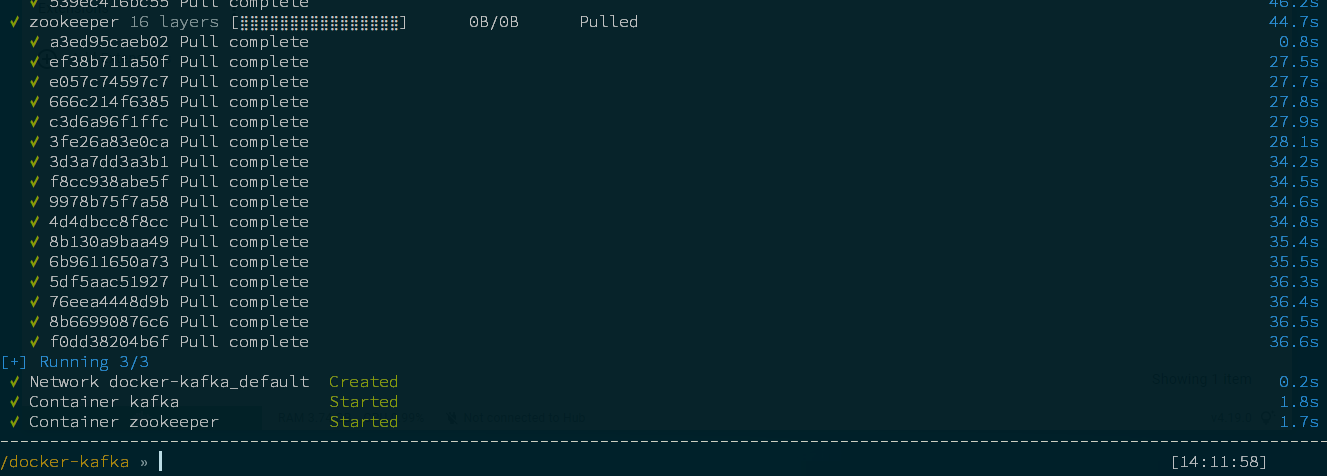
$ docker ps -a [14:33:59]
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
NAMES
4eddc8e49422 provectuslabs/kafka-ui "/bin/sh -c 'java --…" 55 seconds ago Up 48 seconds 8080/tcp, 0.0.0.0:8090->8090/tcp
kafka-ui
dc363b4ef07b wurstmeister/kafka "start-kafka.sh" 55 seconds ago Up 48 seconds 0.0.0.0:9092->9092/tcp
kafka
e0aece9e9142 wurstmeister/zookeeper "/bin/sh -c '/usr/sb…" 55 seconds ago Up 48 seconds 22/tcp, 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp zookeeper
컨테이너 로그 보기
$ docker container logs kafka
$ docker container logs zookeeper
$ docker container logs kafka-ui
kafka 접속
$ docker container exec -it kafka bash
root@d1b20c87d67d:/#
kafka 설정 파일들 확인하기
root@2a0c59c75bb3:/# ls /opt/kafka/config
connect-console-sink.properties connect-file-source.properties consumer.properties server.properties
connect-console-source.properties connect-log4j.properties kraft tools-log4j.properties
connect-distributed.properties connect-mirror-maker.properties log4j.properties trogdor.conf
connect-file-sink.properties connect-standalone.properties producer.properties zookeeper.properties
kafka topic 관련 설정
root@2a0c59c75bb3:/# vim /opt/kafka/config/server.properties
bash: vim: command not found
root@2a0c59c75bb3:/# apt-get update
root@2a0c59c75bb3:/# apt-get install vim
root@2a0c59c75bb3:/# vim /opt/kafka/config/server.properties
# 맨 아래 라인에 추가
delete.topic.enable=true # 토픽 삭제 가능 여부 (default : false)
kafka 재시작
root@2a0c59c75bb3:/# docker restart kafka
topic 생성하기
root@d1b20c87d67d:/# kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic payment-topic
Created topic payment-topic.
kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test-topic
topic 목록 확인하기
root@d1b20c87d67d:/# kafka-topics.sh --list --bootstrap-server localhost:9092
payment-topic
topic 삭제
root@d1b20c87d67d:/# kafka-topics.sh --delete --zookeeper localhost:9092 --topic payment-topic
컨테이너 종료
$ docker-compose down
Server에 설치
host설정
vim /etc/hosts
192.168.10.174 kafka1 zkp1
192.168.10.175 kafka2 zkp2
192.168.10.176 kafka3 zkp3
Java install
# cat <<'EOF' > /etc/yum.repos.d/adoptopenjdk.repo
[AdoptOpenJDK]
name=AdoptOpenJDK
baseurl=http://adoptopenjdk.jfrog.io/adoptopenjdk/rpm/centos/$releasever/$basearch
enabled=1
gpgcheck=1
gpgkey=https://adoptopenjdk.jfrog.io/adoptopenjdk/api/gpg/key/public
EOF
# yum --showduplicates list adoptopenjdk-11-hotspot
# yum install adoptopenjdk-11-hotspot-11.0.11+9-3.x86_64
java 원본 경로 확인
# which javac
/usr/bin/javac
# readlink -f /usr/bin/javac
/usr/lib/jvm/adoptopenjdk-11-hotspot/bin/javac
# vim /etc/profile
...
맨 아래에 JAVA_HOME은 Java설치 경로에서 bin/javac 경로를 제외하고 설정하고 path는 /bin을 포함 시켜준다.
export JAVA_HOME=/usr/lib/jvm/adoptopenjdk-11-hotspot
export PATH=$PATH:$JAVA_HOME/bin
재부팅
# shutdown -r now
카프카 주키퍼 방화벽 설정
## 2181 : Zookeeper Client가 Zookeeper에 연결할 때 사용
# sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address=192.168.10.0/24 port port="2181" protocol="tcp" accept'
## 2888 : Zookeeper leader노드가 follower 노드를 위해 열어두는 포트(동기화용)
# sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address=192.168.10.0/24 port port="2888" protocol="tcp" accept'
## 3888 : Zookeeper 리더 선출을 위한 election 용 포트
# sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address=192.168.10.0/24 port port="3888" protocol="tcp" accept'
## 9092 : Kafka 기본 포트
# sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address=192.168.10.0/24 port port="9092" protocol="tcp" accept'
# firewall-cmd --permanent --zone=public --remove-service=ssh
# sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.10.0/24" port port="7979" protocol="tcp" accept'
## 방화벽 재시작
# firewall-cmd --reload
success
# firewall-cmd --list-all
오픈 가한 파일 최대 개수 & 메모리 LOCK 설정
/etc/security/limits.conf 아래 내용 추가
* soft nofile 65536
* hard nofile 65536
* soft memlock unlimited
* hard memlock unlimited
또는
kafka서비스 계정 설정
kafka soft nofile 65536
kafka hard nofile 65536
kafka soft memlock unlimited
kafka hard memlock unlimited
ulimit -a 또는 ulimit -n 으로 확인
vm.swappiness 설정
vm.swappiness는 메모리 영역을 스왑 영역으로 옮기는 비율을 결정하는 파라미터이다.
이 값이 높아지면 캐시 영역이 여유가 있음에도 불구하고 스왑 영역을 사용하게 되므로 불필요한 스와핑이 발생하고 Disk I/O가 발생하므로 성능에 영향을 끼친다.
처리량이 높은 어플리케이션에서 vm.swappiness = 1로 설정하는 이유는 메모리 재할당 과정 속에서 불필요한 스와핑을 줄이고, 가능한 캐시영역을 비우고 스왑을 사용하고자 함이다.
0이 아닌 1로 설정하는 이유는
0으로 설정하면 1로 설정했을 때보다 훨씬 더 많은 page cache를 해제하게 되는데, page cache를 지나치게 버리면 I/O가 높아지고 시스템의 load를 상승시킬 수 있다고 한다.
/etc/sysctl.conf 파일에서 다음 속성을 지정한다.
vm.swappiness=1
Zookeeper Install
# cd /usr/local
# wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.1/apache-zookeeper-3.8.1-bin.tar.gz
# tar zxf apache-zookeeper-3.8.1-bin.tar.gz
# ln -s apache-zookeeper-3.8.1-bin zookeeper
트랜잭션 로그 등이 저장될 공간 생성
# mkdir -p /data/zookeeper
kafka 노드 ID 설정 (서버에 따라 번호 붙이기 kafka1 : 1, kafka2 : 2, kafka3 : 3 이런식으로)
# echo 1 > /data/zookeeper/myid
zookeeper 설정
# cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
# vim /usr/local/zookeeper/conf/zoo.cfg
맨 아래 줄에 server 정보 추가.
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/zookeeper
# the port at which the clients will connect
clientPort=2181
# Add Kafka Instance Server
server.1 = kafka1:2888:3888
server.2 = kafka2:2888:3888
server.3 = kafka3:2888:3888
zookeeper 시작 / 중지
# /usr/local/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
# /usr/local/zookeeper/bin/zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
zookeeper Service 등록하기
# vim /etc/systemd/system/zookeeper-server.service
[Unit]
Description = zookeeper-server
After = network.target
[Service]
Type = forking
User = root
Group = root
SyslogIdentifier = zookeeper-server
WorkingDirectory = /usr/local/zookeeper
Restart = always
RestartSec = 0s
ExecStart = /usr/local/zookeeper/bin/zkServer.sh start
ExecStop = /usr/local/zookeeper/bin/zkServer.sh stop
[Install]
WantedBy=multi-user.target
systemctl enable zookeeper-server.service
systemctl daemon-reload
systemctl start zookeeper-server
systemctl status zookeeper-server
Kafka Install
# cd /usr/local
# wget https://downloads.apache.org/kafka/3.3.2/kafka_2.13-3.3.2.tgz
# tar -xzvf kafka_2.13-3.3.2.tgz
# ln -s kafka_2.13-3.3.2 kafka
log 디렉토리 생성
# mkdir -p /data/kafka
kafaka 설정
# vim /usr/local/kafka/config/server.properties
log.retention.hour(default: 168, 7일) 로그 파일을 삭제하기 전에 보관하는 시간(시간) -> 3일정도로 하자.
retention.bytes는 로그의 최대 크기를 의미함
delete.topic.enable=true : 만약 허용하지 않는다면 삭제를 하더라도 삭제되지 않고 삭제 표시만 남게 됨.
allow.auto.create.topics=false : Producer가 메시지를 보낼 때 토픽이 생성되어 있지 않으면 자동생성하는 옵션인데, 개발자의 실수로 토픽명이 잘못될 경우 관리자가 알지 못하는 토픽이 자동으로 생길 수 있으므로 명시적으로 생성하여 사용하는 것이 좋음.
broker.id=1
...
log.dirs=/data/kafka
listeners=PLAINTEXT://:9092 #주석 해제
default.replication.factor=3
min.insync.replicas=2
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
transactional.id.expiration.ms = 259200000
...
zookeeper.connect=zkp1:2181,zkp2:2181,zkp3:2181
transactional.id.expiration.ms = 259200000 (2일)
int형으로 최대 약 21억ms까지 가능하며, transactional.id.expiration.ms가 클 수록 메모리를 많이 사용한다.
kafka transaction 만료일(기본: 7일), 7일동안 메시지가 발급 안되면 7일 이후 발급 시 오류
InvalidPidMappingException
The producer attempted to use a producer id which is not currently assigned to its transactional id.
해결: transactional.id.expiration.ms를 2일로 지정하고, 각 application producer에서 스케쥴러로 1일에 한번씩 warmup 토픽을 발행한다.
위 처럼 zookeeper.connect에 zookeeper 서버 정보를 입력하면 서로 다른 어플리케이션에서 동일한 지노드를 사용하게 될 경우, 데이터 충돌이 발생할 수 있어서, 하나의 주키퍼 앙상블 세트와 하나의 어플리케이션만 사용하는 것을 권장한다고 한다. 여러 개의 어플리케이션이 하나의 주키퍼 앙상블 세트에 접근하는 것이 잘못된 방법은 아니지만, 약간의 설정을 변경해 주키퍼 앙상블 세트를 여러 개의 어플리케이션에서 공용으로 사용할 수 있도록 아래와 같이 호스트 정보 뒤에 / 지노드명을 넣어서 설정하자.
delivery 프로젝트 하나만 kafka를 사용하는 경우
## kafka1 서버
zookeeper.connect = zkp1:2181,zkp2:2181,zkp3:2181/kafka-delivery
## kafka2 서버
zookeeper.connect = zkp1:2181,zkp2:2181,zkp3:2181/kafka-delivery
## kafka3 서버
zookeeper.connect = zkp1:2181,zkp2:2181,zkp3:2181/kafka-delivery
delivery, mart 두개의 프로젝트에서 kafka를 같이 사용하는 경우(zookeeper 호스트는 중복이 안된다고 한다..)
## kafka1 서버
zookeeper.connect = zkp1:2181,zkp2:2181/kafka-delivery,zkp3:2181/kafka-mart
## kafka2 서버
zookeeper.connect = zkp1:2181,zkp2:2181/kafka-delivery,zkp3:2181/kafka-mart
## kafka3 서버
zookeeper.connect = zkp1:2181,zkp2:2181/kafka-delivery,zkp3:2181/kafka-mart
서비스 등록
# vim /etc/systemd/system/kafka-server.service
[Unit]
Description = kafka-server
Requires=network.target zookeeper-server.service
After = network.target zookeeper-server.service
[Service]
Type = simple
User = root
Group = root
SyslogIdentifier = kafka-server
WorkingDirectory = /usr/local/kafka
LimitNOFILE=65536
LimitMEMLOCK=infinity
Environment="KAFKA_HEAP_OPTS=-Xmx2G -Xms2G"
Environment="KAFKA_OPTS=-javaagent:/usr/local/kafka/jmx_prometheus_javaagent-0.19.0.jar=7071:/usr/local/kafka/kafka_broker.yml"
Environment="KAFKA_JMX_OPTS=-Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=kakfa1 -Djava.net.preferIPv4Stack=true"
Restart = always
RestartSec = 0s
ExecStart = /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
ExecStop = /usr/local/kafka/bin/kafka-server-stop.sh
[Install]
WantedBy=multi-user.target
systemctl enable kafka-server
systemctl daemon-reload
systemctl start kafka-server
systemctl status kafka-server
시작은 zookeeper -> kafka 순
systemctl start zookeeper-server
systemctl start kafka-server
종료는 kafka -> zookeeper 순
systemctl stop kafka-server
systemctl stop zookeeper-server
Kafka 실행 중 오류가 발생한 경우 (server.log)
InconsistentClusterIdException: The Cluster ID c_T_P8jVRPmYHk9Q1SY--A doesn't match stored clusterId Some(dP88YPU0Rf2fRmX3mA07mQ) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
/usr/local/kafka/config/server.properties에 설정된 log.dirs의 meta.properties를 삭제하고 재시작.
Cluster 확인하기
zkp1 서버
#/usr/local/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
zkp2 서버
#/usr/local/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
zkp3 서버
#/usr/local/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
서버에 Kafka-ui 설치
https://github.com/provectus/kafka-ui
mkdir /docker-kafka-ui
cd /docker-kafka-ui
vim docker-compose-kafka-ui.yaml
version: '2'
services:
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "7979:8080"
extra_hosts:
- 'kafka1:192.168.10.174'
- 'kafka2:192.168.10.175'
- 'kafka3:192.168.10.176'
- 'zkp1:192.168.10.174'
- 'zkp2:192.168.10.175'
- 'zkp3:192.168.10.176'
restart: always
environment:
- KAFKA_CLUSTERS_0_NAME=local
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka1:9092,kafka2:9092,kafka3:9092
- KAFKA_CLUSTERS_0_ZOOKEEPER=zkp1:2181,zkp2:2181,zkp3:2181
docker-compose -f docker-compose-kafka-ui.yaml up -d
재빌드
docker-compose -f "docker-compose-kafka-ui.yaml" up -d --build
실행 로그 보기
docker container logs kafka-ui
kafka-ui 컨테이너로 접속하기
docker container exec -it kafka-ui /bin/sh
# docker inspect kafka-ui
# docker container logs kafka-ui > kafka-ui-logs.txt
# docker-compose -f "docker-compose-kafka-ui.yaml" restart kafka-ui
Restarting kafka-ui ... done
# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0d3e0c2d299a provectuslabs/kafka-ui "/bin/sh -c 'java --…" 5 months ago Up 10 seconds 0.0.0.0:7979->8080/tcp, :::7979->8080/tcp kafka-ui
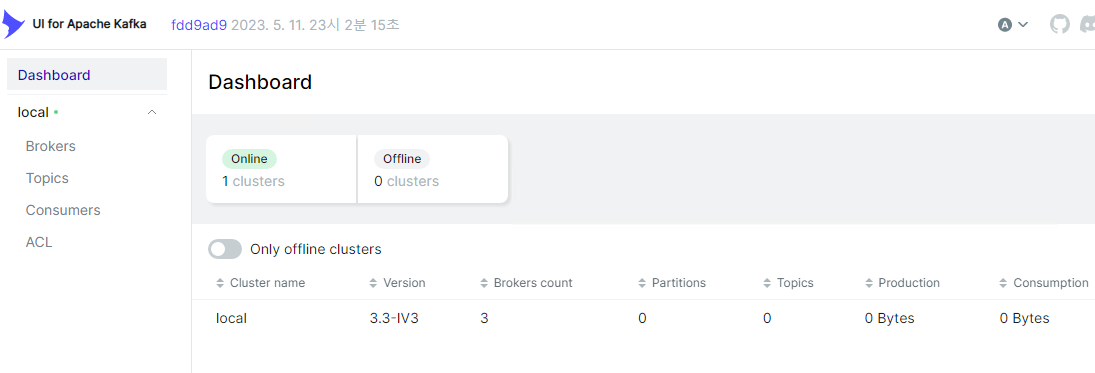
Kafka-ui에서 Cluster 확인
메인 페이지에 clusters가 online으로 표시
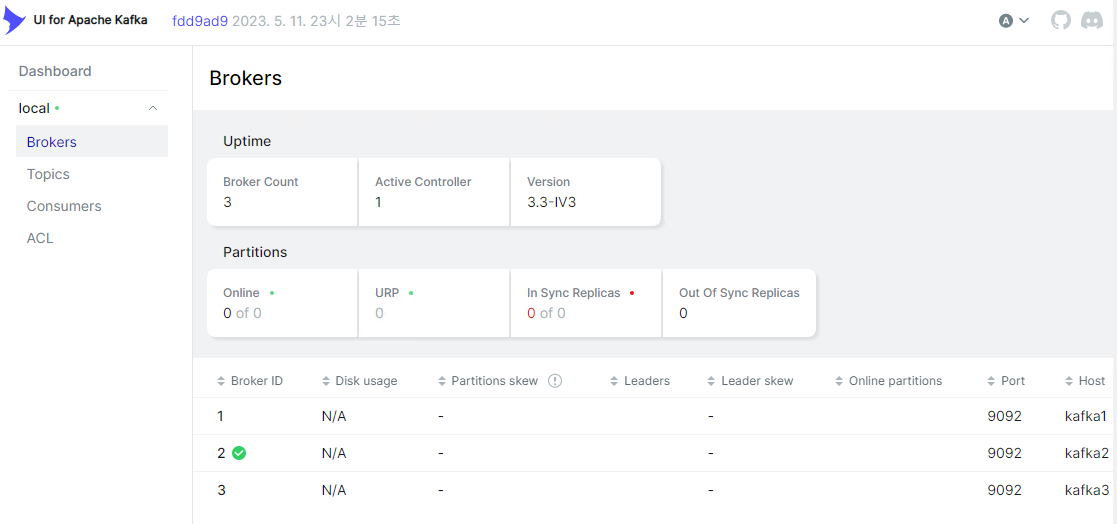
Brokers에 clusters로 연결된 Broker 3개가 표시
테스트 토픽을 생성
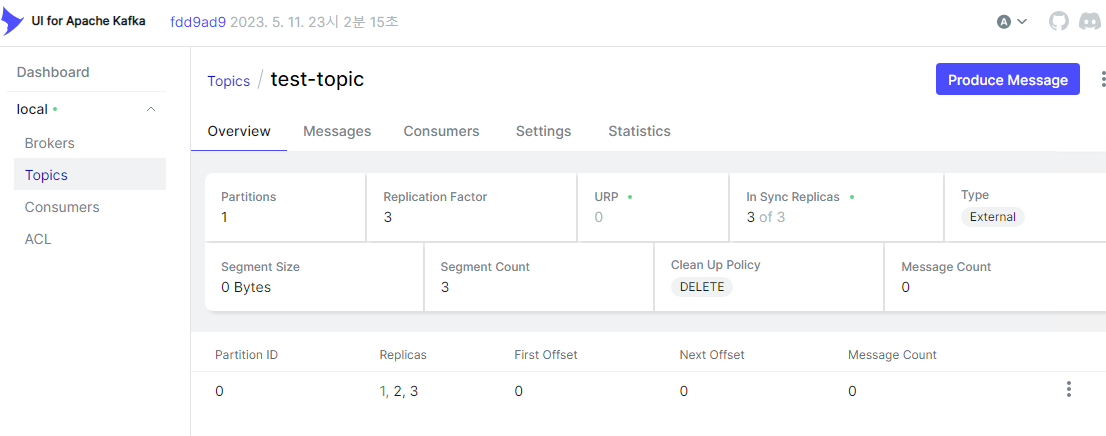
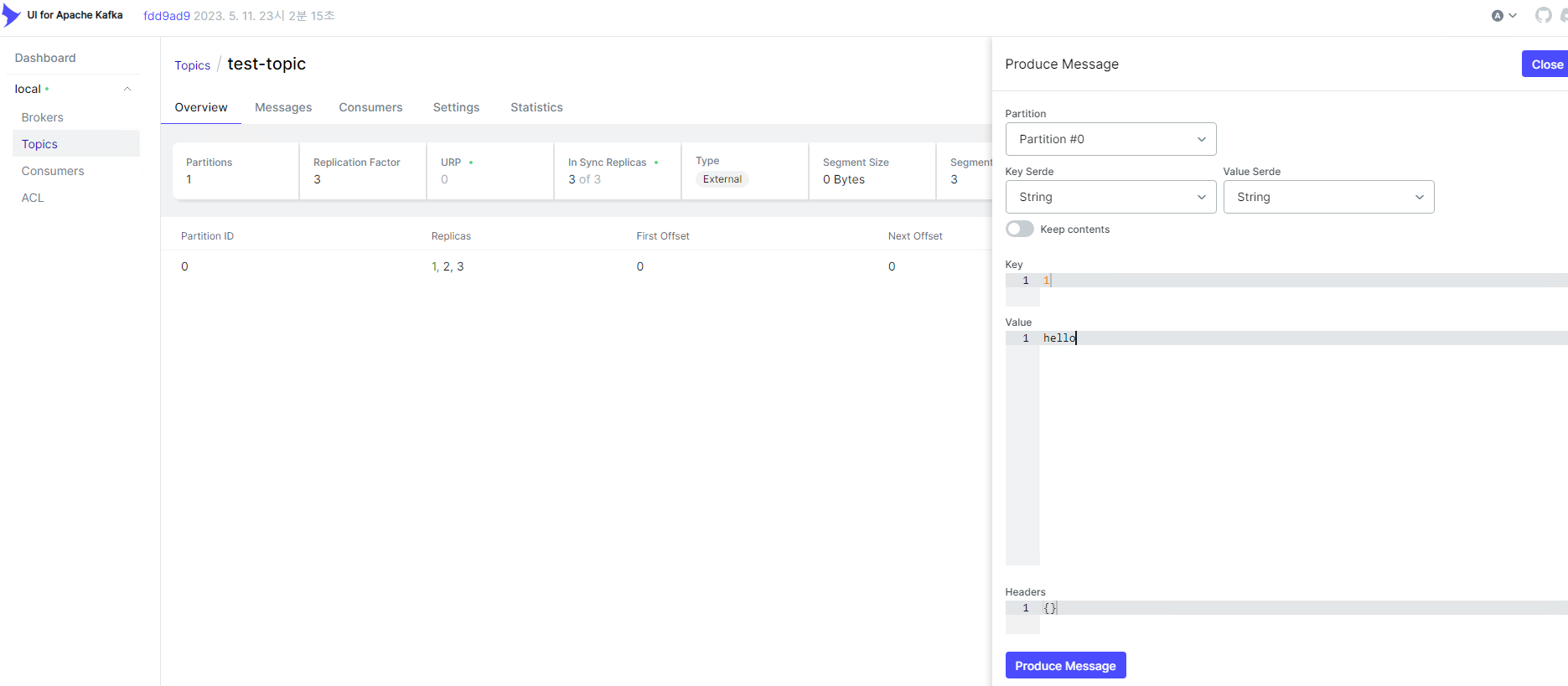
우측 상단 Produce Message로 메시지를 발행
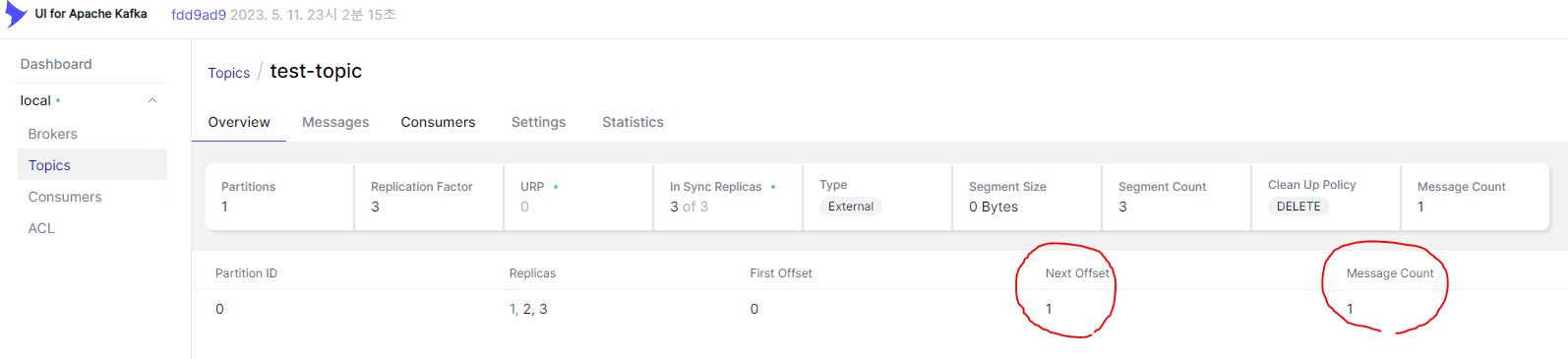
메시지가 발행된 것을 확인할 수 있다.
서버에서 해당 토픽도 확인할 수 있다.
kafka1# ls /data/kafka
cleaner-offset-checkpoint meta.properties replication-offset-checkpoint
log-start-offset-checkpoint recovery-point-offset-checkpoint test-topic-0
[root@kafka1 kafka]# cd test-topic-0/
kafka1# ls /data/kafka/test-topic-0
00000000000000000000.index 00000000000000000000.timeindex partition.metadata
00000000000000000000.log leader-epoch-checkpoint
References
Kafka 공식 Document, Kafka 공식 v3.3 Document
Apache Kafka 클라이언트에 권장되는 구성 - Microsft.com
리밸런싱이 자주 일어나는 경우 - CommitFailedException에 대해
https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/kafka_system_level_broker_tuning.html
댓글남기기