세션 저장소
웹서비스를 담당하고 있는 서버로 수 많은 클라이언트가 접속하여 감당할 수 없는 상태가 되면 서버의 하드웨어를 업그레이드 시키거나(Scale-Up) 서버를 추가(Scale-Out)하여 이를 해결할 수 있습니다.
Scale-Up방식
서버의 CPU, 메모리, 하드디스크 등의 하드웨어를 업그레이드 하거나 추가하여 성능을 향상 시키는 방법을 말합니다.
장점: 데이터 정합성 이슈에서 자유롭고, 라이센스 추가 비용이 적습니다. (특정 라이센스는 하드웨어 스펙에 따라 가격을 책정 합니다.)
단점: 단일 서버에 대해 추가할 수 있는 하드웨어 수가 제한적이고 고성능의 하드웨어일 수록 가격이 엄청 비싸집니다. 그리고 일정 수준이 넘어가면 하드웨어 업그레이드가 성능이 미치는 폭이 작아집니다.
ACID(원자성, 일관성, 고립성, 지속성)를 지켜야하는 관계형 데이터베이스 서버는 Scale-Up이 유리합니다.
Scale-Out방식
동일한 스펙의 서버를 추가하여 서버의 성능을 향상시키는 방법입니다. 이를 위해서는 Load Blancer로 서버의 로드율, 부하량, 처리속도 등을 고려하여 트래픽을 여러 서버로 분산시키는 것이 필요하고, 각 서버 간의 세션 정보를 공유할 수 있는 수단이 필요합니다.
장점: Scale-Up방식에 비해 하드웨어 가격이 저렴하지만 라이센스 비용이 증가할 수 있기 때문에 오픈 라이센스를 사용해야 가격을 줄일 수 있습니다.
단점: 각 서버 간의 세션 등의 정보를 공유할 수 있는 수단이 없다면 데이터 불일치 문제가 발생할 수 있습니다.
웹서버와 같이 트랜잭션 처리는 단순하지만 다수의 처리를 동시 병렬적으로 처리 해야되는 서버는 Scale-Out 방식이 유리합니다.
Scale-Out 방식에서 발생할 수 있는 세션 정보의 불일치 문제를 해결하기 위해서는 각 서버에서 세션을 생성하고 관리하는 것이 아니라 공통으로 세션을 관리하는 별도의 세션 서버를 구성해야 됩니다.
Sticky Session 방식
Load Balancer가 세션을 생성한 서버로만 요청을 보내는 방식입니다. 세션을 생성한 서버 정보를 쿠키를 통해 전송되고 이후 클라이언트 요청이 들어오면 Load Balancer가 헤더에서 쿠키 값을 읽어서 해당 서버로 리다이렉트 시켜줍니다. 이 방식은 세션이 유지되는 동안 동일 서버만 사용하기 때문에 정합성 이슈에서는 자유로워 지지만 고정 세션을 사용하므로서 특정 서버에 트래픽이 집중될 수 있는 위험성이 있습니다. 또한 해당 서버의 장애가 발생할 경우 해당 서버의 세션정보를 모두 잃어 버리게되므로 가용성이 떨어지게 됩니다.
WAS를 이용한 Session Clustering
특정 서버에 session이 생성되면 각 서버에 세션 복제(Session Replication)를 하여 어떤 서버로 접속하더라도 세션정보를 이용할 수 있는 방법입니다. 특정 서버에 장애가 발생하여도 서비스는 문제 없이 이용할 수 있는 장점이 있지만 모든 서버에 세션 객체를 생성해야 하기 때문에 많은 메모리를 사용하게 됩니다. 또한 서버의 수가 증가할 수록 세션 복제 대상이 증가 하기 때문에 네트워크 트래픽이 증가하는 등의 성능 저하가 발생하게 됩니다. Tomcat에서는 이러한 문제를 극복하기 위해 BackupManager를 이용해서 Primary-Secondary 세션 복제 방식을 제공합니다. 이 방식은 모든 서버에 세션을 복제하는 것이 아니라 Primary와 Secondary서버 간에만 세션 객체를 복제하고 그 외 서버는 세션의 Key값만 복제합니다. 이런식으로 메모리나 트래픽을 줄일 수는 있지만 Primary와Secondary 서버 이외 서버로 요청이 오면 다시 복제 작업이 필요하게 됩니다. 또한 Session Clustering 방식은 네트워크 속도 지연 등으로 서버 간의 세션 불일치 문제가 발생할 수도 있습니다.
세션 저장소 분리 방식
각 서버에서 세션 정보를 관리하는 것이 아니라 별도의 서버에서 세션을 관리 하도록 구성하고 각 서버가 이를 참조 하도록 하는 방식입니다. 이 방식은 트래픽이 특정 서버로 집중되지 않고 특정 서버의 장애에도 서비스에 문제가 발생하지 않는 가용성을 확보할 수 있습니다. 뿐만 아니라 서버간의 세션 복제가 필요 없으므로 서버 간의 세션 불일치 문제도 해결됩니다. 단 단일 세션 서버로만 구성하면 장애시 모든 서비스에 문제가 발생하므로 Master-Slave 형태의 백업 세션 서버를 구성하고 Replication을 해야 장애시 FailOver가 작동하여 안정적으로 서비스를 운영할 수 있습니다.
세션 저장소는 웹 서비스 특성상 사용자 인증을 확인하는 절차로 세션 저장소를 자주 접근하여 세션을 Read해야 합니다. 이런 특성을 고려하여 빠르게 데이터를 찾아서 제공해줄 수 있는 데이터베이스는 디스크 기반의 데이터베이스와 In-Memory 데이터베이스가 있습니다.
디스크 기반의 데이터베이스: MySQL, Oracle, SQL Server 등
In-Memory 데이터 베이스: Amazon ElastiCache, Redis, Memcached 등
디스크 기반의 데이터베이스를 SSD기반으로 빠른 I/O를 처리할 순 있지만 메모리로 사용하는 RAM은 SSD보다 약 1000배 정도가 빠르기 때문에 메모리로 100만건을 1초에 처리한다면 SSD로는 100만건 처리하는데 17분이 걸리게 됩니다. 웹 서비스에서 대량의 인증 정보를 빠르게 Read/Write 해야되기 때문에 메모리가 더 적합하다는걸 알 수 있습니다.
하지만 메모리는 휘발성이므로 전원이 OFF되면 모든 정보가 없어지기 때문에 문제가 발생할 수 있습니다. 이러한 문제는 세션 서버를 Master-Slave로 구성하고 Replication을 통해 해결 할 수 있으며 Master가 장애가 발생하면 Slave 서버가 Master로 승격시켜 서비스를 중단 없이 지속적으로 운영할 수 있습니다.
세션 저장소로 적합한 In-Memory 데이터베이스로 Redis를 선택하였는데 그 이유는 빈번한 Read/Write를 안정적으로 처리할 수 있고, Replication 기능을 지원하기 때문에 더 쉽게 Fail Over 기능을 구현할 수 있습니다. 또한 key-Value 저장소이지만 Value에 List, Set, Sorted Set 등 다양한 자료구조를 지원하고, 스프링에서 Redis API를 지원하기 때문에 Spring framework를 이용하여 개발 시에 쉽게 적용할 수 있다는 점이었습니다.
추가적으로 Redis 사용 시 아래와 같은 유의사항들이 있습니다.
-
jemalloc 알고리즘을 사용하여 매번 malloc와 free를 통하여 메모리를 할당 해제하기 때문에 내부 단편화 문제가 발생할 수 있습니다. 1byte가 필요하더라도 페이지 단위로 메모리를 할당 하기 때문에 페이지 단위가 클수록 사용되지 않는 메모리가 늘어 납니다.
-
Redis가 Single Thread로 작동하기 때문에 병목현상이 발생할 순 있지만 데이터가 메모리에 저장되고 관리되기 때문에 CPU가 Redis에서 병목현상을 발생시키는 빈도는 적습니다.
(병목현상: 처리할 수 있는 양보다 많은 데이터가 유입되면서 시스템이 느려지는 현상)
-
Redis는 Linux 환경에서 파이프라인을 사용하면 초당 약 100만건의 요청을 전달 가능하고 응용프로그램이 O(N) 혹은 O(log(N)) 정도의 연산을 한다면 CPU에 큰 부담을 주는 것은 아니라고 합니다.
-
더 많은 CPU를 사용하고 싶다면 Replication과 Sharding을 활용하여 Redis의 인스턴스를 증가시키고, 각 인스턴스로 데이터를 분산시켜서 사용하면 가능합니다.
Redis 처리 성능
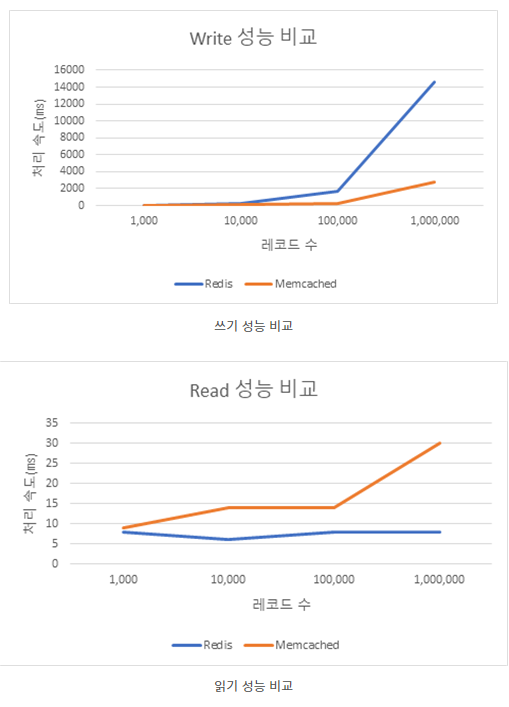
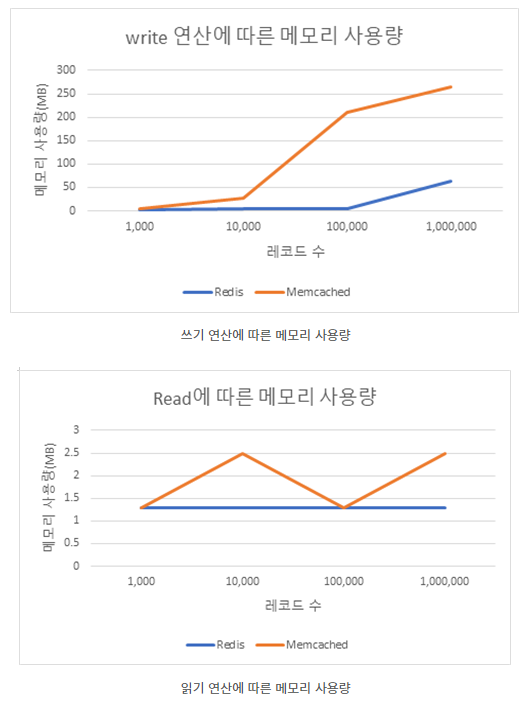
참고
댓글남기기