Sping Boot Elasticsearch 연동
Spring Boot에서 Spring Data Elasticsearch를 이용해 Elasticsearch와 연동할 수 있다.
그 전에 Spring Boot 버전과 Elasticsearch 버전이 호환되는지 확인 후에 진행해야 한다.
Spring 공식 문서에 다음과 같이 버전 호환성을 표기되어 있다.
https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html/
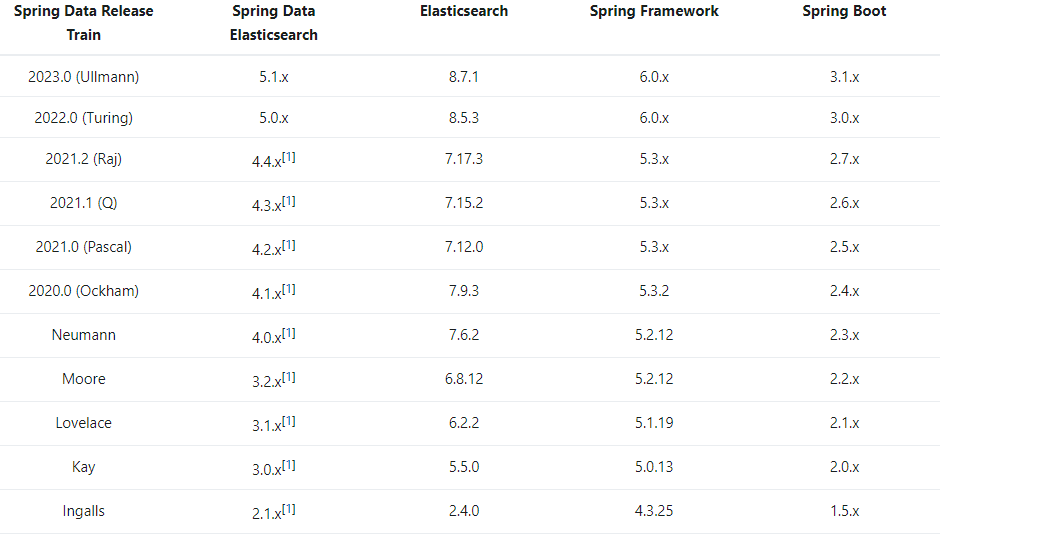
최신 Elasticsearch 8.x 버전을 사용하려면 Spring Boot 3 이상을 사용해야 되고, Java 17이 필요하다. (https://spring.io/blog/2022/05/24/preparing-for-spring-boot-3-0)
이점을 잘 고려하여 Elasticsearch 버전을 선택해야 한다.
추가적으로 Spring boot에서 Elasticsearch를 사용하기 위한 방법이 몇 가지 존재한다.
- rest-high-level-client
- 관련 문서가 많고 많은 기능을 제공함.
- spring boot 버전과 관계 없이 사용 가능하지만 spring data elasticsearch보단 코드량이 증가함.
- Elasticsearch 7.15.0 버전에서 Deprecated 됨.
-
Spring Data Elasticsearch
- rest-high-level-client 를 기반으로 spring에서 만든 라이브러리.
- ORM을 지원해서 JPA를 사용할 때처럼 보일러 코드가 줄어 듬.
- spring 버전에 따른 dependency 제약. (spring boot 버전에 따른 elasticsearch, java 버전을 고려해야 함)
- Elasticsearch Java API Client
-
7.16 이후 rest-high-level-client를 대체한 Elastic 사에서 개발한 Java Client 모듈.
- 자세한 내용: https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/current/index.html
이번 블로그에서는 다음과 같은 스펙으로 진행한다.
- Java 17
- Spring Boot 3.1.1
- Elasticsearch 8.7.1
- Spring Data Elasticsearch
페이징
NativeQueryBuilder nativeQueryBuilder = new NativeQueryBuilder();
nativeQueryBuilder.withPageable(PageRequest.of(dto.getPageNo(), dto.getRowNum()));
...
SearchHits<SearchResponseItem> searchHits = elasticsearchOperations.search(nativeQueryBuilder.build(), SearchResponseItem.class);
조회 개수가 10000개를 넘아가는 순간 Elasticsearch 에서는 에러를 발생.
from 과 size 를 활용한 Pagination 은 분산된 Shard 부터 요청된 데이터를 메모리에 올려서 찾고 모아서 정렬 작업을 한 후 클라이언트가 요청한 Page 를 반환하기 때문에 10000 개가 넘는 데이터를 조회할 수 없도록 막고 있다
이를 해결하기 위해 를 기본값인 10000개가 넘도록 설정하는 것도 하나의 방식일 수 있겠지만 이는 메모리 및 성능상 이슈를 야기시킬 수 있기 때문에 권장되지 않는 방식이다. (최대 50000개 까지 설정 가능)
Spring Data Elasticsearch 를 활용한 Search After 기능 활용하기
Enum 사용
@Getter
@RequiredArgsConstructor
@JsonFormat(shape = JsonFormat.Shape.OBJECT)
public enum DeliveryType implements ConverterEnum {
DELIVERY("1", "DELIVERY", "배달"),
PICKUP("2", "PICKUP", "포장"),
DELIVERY_PICKUP("3", "DELIVERY_PICKUP", "배달+포장");
private final String code;
private final String enumCode;
private final String codeName;
private static final Map<String, DeliveryType> stringToEnum =
Stream.of(values()).collect(toMap(DeliveryType::getCode, e -> e));
@JsonValue
public String getEnumCode() {
return this.codeName;
}
@JsonCreator
public static DeliveryType of(String code) {
return stringToEnum.get(code);
}
}
@WritingConverter
public class DeliveryTypeWriteConverter implements Converter<DeliveryType, String> {
@Override
public String convert(DeliveryType source) {
return source.getCode();
}
}
@ReadingConverter
public class DeliveryTypeReadConverter implements Converter<String, DeliveryType> {
@Override
public DeliveryType convert(String code) {
return EnumSet.allOf(DeliveryType.class).stream()
.filter(e -> e.getCode().equals(code))
.findFirst()
.orElseThrow(() -> new IllegalArgumentException(
String.format("elasticsearch에서 읽은 %s 코드값이 DeliveryType enum에 존재하지 않습니다.",
code)));
}
}
@Configuration
public class CustomConversionsConfig {
@Bean
public ElasticsearchCustomConversions elasticsearchCustomConversions() {
return new ElasticsearchCustomConversions(
Arrays.asList(new DeliveryTypeReadConverter(), new DeliveryTypeWriteConverter())
);
}
}
@Document(indexName = "shop_index")
public class SearchResponseItem {
private Long shopSeq;
private DeliveryType deliveryType;
...
}
SearchHits<SearchResponseItem> searchHits = elasticsearchOperations.search(nativeQueryBuilder.build(), SearchResponseItem.class);
Highlighting settings
https://www.elastic.co/guide/en/elasticsearch/reference/current/highlighting.html#unified-highlighter
POST /shop_index/_update/11?refresh=false
refresh=true:- 장점:
- 변경된 문서를 즉시 검색 가능하게 만듭니다. 즉, 데이터를 인덱싱한 직후에 검색이 가능합니다.
- 실시간 검색이 중요한 애플리케이션에서 유용합니다. 데이터 변경이 거의 없는 경우에는 빠른 검색 결과를 얻을 수 있습니다.
- 단점:
refresh작업은 상대적으로 많은 시스템 리소스를 소비하며, 빈번한refresh는 성능 저하를 야기할 수 있습니다.- 변경이 자주 일어나는 환경에서 자주 사용하면 인덱싱 성능이 저하될 수 있습니다.
- 장점:
refresh=false:- 장점:
refresh작업을 지연하여, 인덱싱 성능을 향상시킬 수 있습니다. 변경된 데이터가 일정 시간 동안 버퍼링되어, 리프레시가 집중적으로 실행되어 시스템 리소스를 절약할 수 있습니다.- 대량의 데이터를 일괄적으로 인덱싱하는 경우에 유용합니다.
- 단점:
- 변경된 데이터가 즉시 검색 가능하지 않습니다.
refresh작업을 실행하지 않으면 최신 데이터를 검색할 수 없으며, 약간의 지연이 발생할 수 있습니다. - 실시간 검색이 중요한 애플리케이션에서는 최신 데이터를 제공하지 못하는 문제가 있을 수 있습니다.
- 변경된 데이터가 즉시 검색 가능하지 않습니다.
- 장점:
따라서, refresh=true는 실시간 검색이 중요하거나 변경이 자주 발생하는 환경에서 유용하며, refresh=false는 대량의 데이터를 처리하거나 인덱싱 성능을 최적화해야 할 때 유용합니다. 애플리케이션의 요구사항과 데이터 업데이트 빈도에 따라 적절한 refresh 방식을 선택하여 사용하는 것이 중요합니다.
인덱스 강제 병합 (인덱스에 데이터를 저장하면 이전 데이터는 자동으로 버전관리되면서 용량이 증가하는데, 강제 병합하게 되면 이를 삭제하여 용량이 줄어듬)
POST /item_index/_forcemerge?max_num_segments=1
전체 인덱스 (종류 및 용량) 확인
GET /_cat/indices
인덱스 삭제
DELETE item_index
인덱스 조회
GET shop_index/_search
{
"_source": {
"excludes": ["_class", "dongSeq", "_class", "categories"
]
}
}
인덱스 내 nested item array 갯수 확인
GET item_index/_search
{
"size": 0,
"aggs": {
"nested_items_count": {
"nested": {
"path": "items"
},
"aggs": {
"item_count": {
"cardinality": {
"field": "items.itemSeq"
}
}
}
}
}
}
References
https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html/
댓글남기기