Spring Cloud(MSA) 구조에서 무중단 롤링 배포
사용 버전
-
Spring Cloud Eureka 3.1.3
-
Spring Cloud Gateway 3.1.3
-
Spring Boot 2.6.6
배포 방식
배포 방식은 주로 롤링, 블루-그린, 카나리 방식을 많이 사용한다.
1. 롤링 배포(Rolling Deployment)
순차적으로 하나씩 배포하는 방식
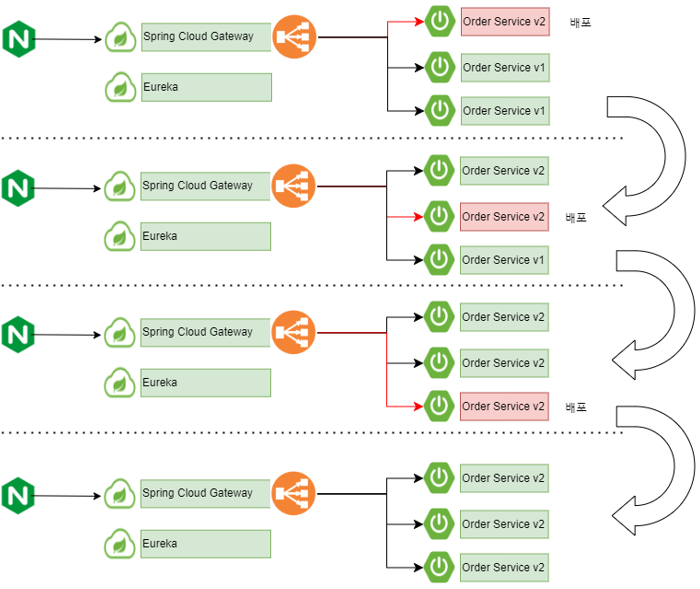
-
장점
- 배포에 추가적인 서버 리소스가 필요 없다.
- 배포 방식이 간단하다.
-
단점
-
한 개씩 배포 하므로 배포 시간 또는 롤백 시간이 다소 걸린다.
-
배포 중 서비스 인스턴스 수가 줄기 때문에 다른 서비스들이 감당해야할 트래픽의 양이 늘어난다.
-
구버전과 신버전의 서비스가 공존하게 되므로 호환성 문제가 발생할수 도 있다.
-
Eureka와 같은 Service Discovery를 사용하면 서비스 목록을 각 서비스에서 일정 시간 마다 캐싱하는데, 캐싱된 정보로 요청을 보내면 배포 중인 서비스로 요청을 보내기 때문에 오류가 발생할 수 있다. 이를 해결하는 추가적인 방법이 필요하다.
-
2. 블루-그린 배포(Blue-Green Deployments)
기존 버전의 프로덕트 환경을 블루(Blue), 신규 버전의 프로덕트 환경을 그린(Green)이라 부른다.
신규 버전 프로덕트 환경(Green)에 모두 배포한 다음 테스트를 진행하여 문제가 없다면 Load Balancer를 Blue에서 Green으로 변경하여 한번에 배포가 완료되는 방식이다.
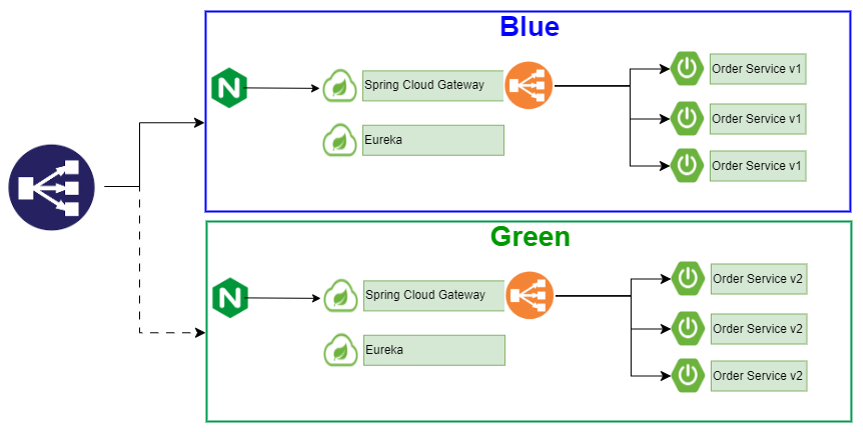
- 장점
- 배포 시간 및 롤백 시간이 빠르다.
- 서비스에 영향을 주지 않고 신규 버전을 프로덕트 환경에서 테스트할 수 있다.
- 롤링 방식과 같은 구버전, 신버전의 호환성 문제가 발생하지 않는다.
- 단점
- 서버 리소스가 두배로 들기 때문에 많이 비용이 발생한다.
3. 카나리 배포(Canary Deployment)
기존 버전의 프로덕트 환경에 신규 버전 서비스를 일부 배포하여 문제가 없는지 확인한 다음 문제가 없으면 전체 배포하는 방식.
- 장점
- 신규 버전에 오류가 발생하여도 전체 유저에게 오류가 전파되지 않는다.
- 빠른 롤백이 가능하다.
- a/b 테스트가 가능하다.
- 단점
- 롤링 배포와 마찬가지로 호환성 문제가 발생할 수 있다.
- L7 Load Balancing 설정 등 복잡성이 올라간다.
- 배포에 시간이 다소 걸린다.
*a/b 테스트: 특정 User 군을 나누어 두가지 버전을 배포하고 트래픽, 클릭수, 호흥도 등의 통계를 기반으로 비지니스 의사 결정을 내리는 기술.
롤링(Rolling Deployment) 배포 방식을 선택
블루-그린 방식을 채택하고 싶었지만 가용할 수 있는 서버 리소스가 부족해서 롤링 배포로 무중단 서비스를 구현해야 했다.
롤링 배포할 때 주의할점은 eureka로 부터 서비스 목록을 캐싱한 spring cloud gateway 또는 서비스들이 down된 서비스로 요청을 보내어 오류가 발생할 수 있기 때문에 별도의 처리가 필요하다.
우선 Eureka를 이용하는 서비스를 배포할 때 발생할 수 있는 문제점을 살펴보자.
Eureka Client로 정의된 하나의 서비스가 시작되면 자동으로 Eureka에 등록된다.
이때 Eureka 엔드포인트를 호출하면 등록된 서비스 정보를 확인할 수 있다.
GET http://localhost:8761/eureka/apps
<applications>
...
<application>
...
<name>MEMBER</name>
<instance>
<instanceId>1c8b5aeaa0c0:member:9093</instanceId>
<hostName>192.168.10.1</hostName>
<app>MEMBER</app>
<ipAddr>192.168.10.1</ipAddr>
<status>UP</status>
<port enabled="true">8080</port>
...
</instance>
</application>
</applications>
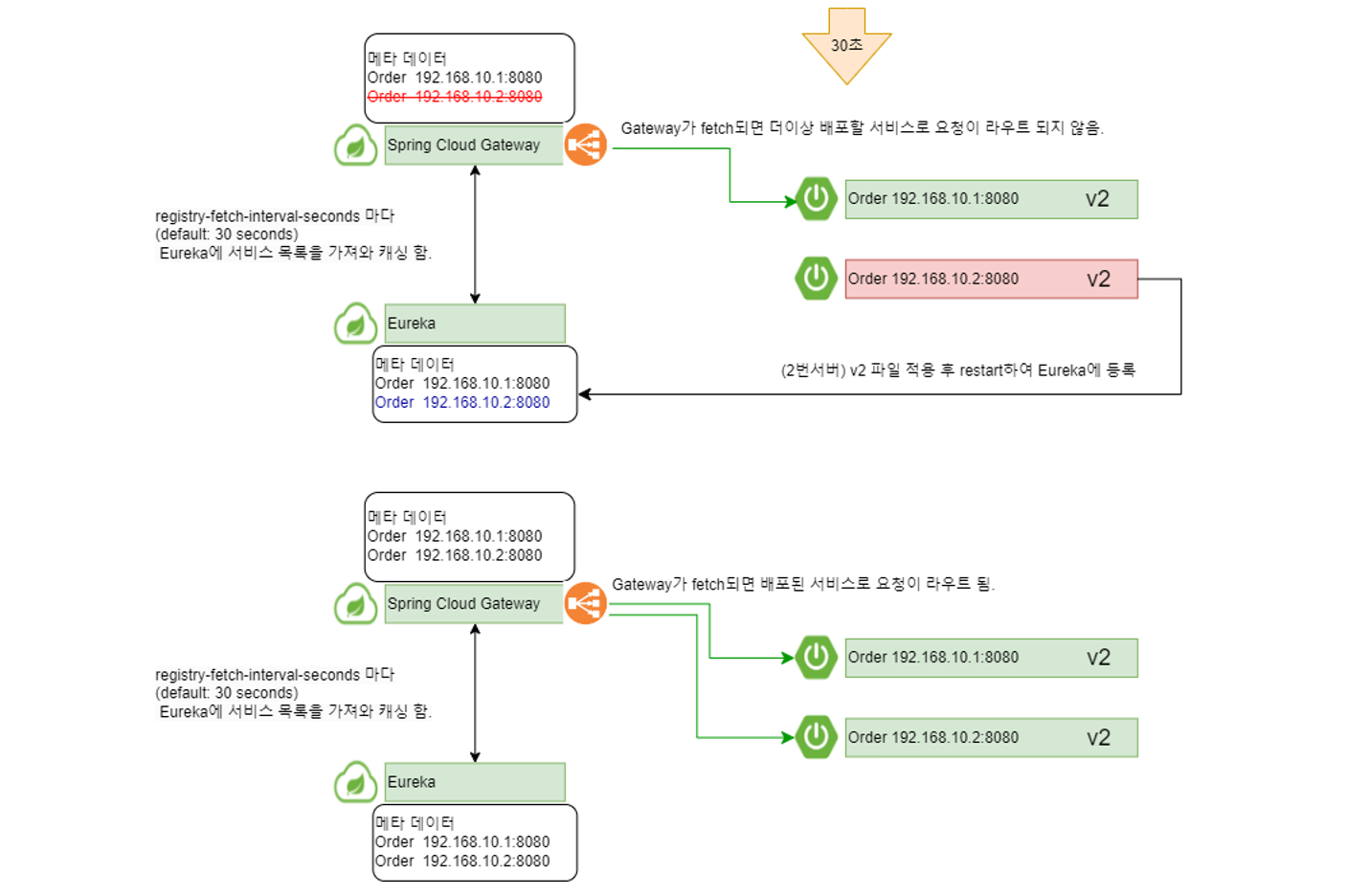
Eureka에 서비스가 등록된 직후 Gateway를 통해서 서비스의 엔드포인트를 요청하면 Gateway의 캐싱된 메터 데이터가 없기 때문에 503 Service Unavailable 오류가 발생하게 된다.
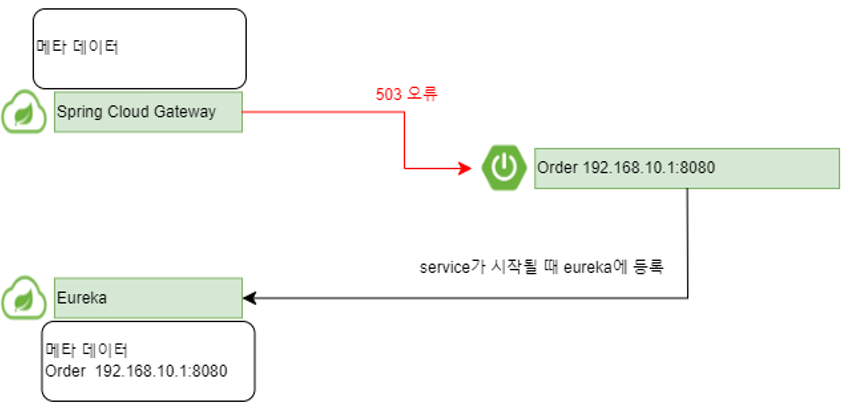
Gateway가 Eureka로 부터 서비스 목록을 fetch하여 캐싱한 다음에서야 서비스의 엔드포인트 요청이 정상적으로 실행된다.
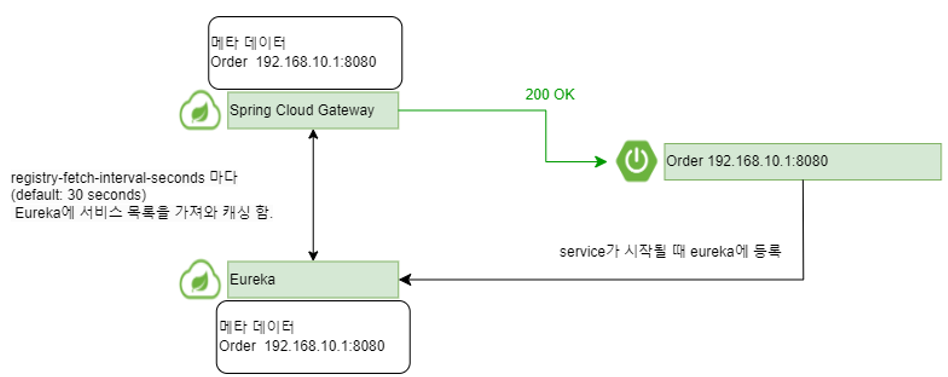
이러한 메커니즘을 유레카 자기 보존(Self Preservation)이라고 한다.
아래와 같이 Gateway가 두 개의 서버를 Load Balancing하고 있을 때, 배포 목적으로 하나의 서버를 Down하게 되면 Gateway는 Eureka에 서비스 목록을 fetch하기 전까지 자신이 가지고 있는 메타 데이터로 Load Balancing하기 때문에 503 Service Unavailable이 발생할 수 있다.
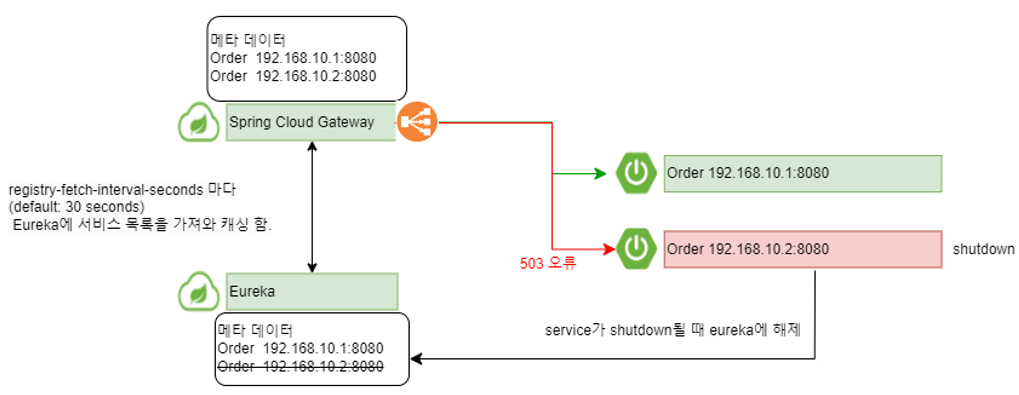
이후 registry-fetch-interval-seconds 주기로 fetch가 되면 정상적으로 shutdown된 서버로 요청을 보내지 않게 된다.

그렇다면 롤링 배포에서 무중단(Zero Downtime)을 실현 위해서 어떻게 해야될까?
-
registry-fetch-interval-seconds 설정
registry-fetch-interval-seconds을 낮은값으로 설정하면 eureka에 짧은 간격으로 fetch하여 빠르게 서비스 목록을 갱신할 수는 있다. 그러나 서버에 부하가 발생할 수 있고 서비스 목록을 갱신하는데 최소한에 시간이 필요하기 때문에 그 사이에 오류가 발생할 수 있기 때문에 이는 해결방안이 아니다.
-
Retry Filter 사용
Retry Filter를 사용하면 down된 서버로 request가 라우트되었을 때 오류가 발생하면 등록된 다른 서버로 요청을 보내도록 할 수 있다. 이 방법은 Nginx가 multiple upstream server를 처리하는 방식과 유사하다. (참고: Nginx Upstream Module)
spring: cloud: gateway: routes: - id: service uri: lb://SERVICE predicates: - Path=/service/** filters: - name: Retry args: retries: 3 # 재시도 횟수 statuses: SERVICE_UNAVAILABLE # 재시도 대상 HttpStatus 상태(org.springframework.http.HttpStatus) methods: GET,POST,DELETE,PUT,PATCH,DELETE # 재시도 대상 HttpMethod backoff: firstBackoff: 10ms # 첫 재시도 시간 maxBackoff: 100ms # 최대 재시도 시간 (retries 숫자 만큼 firstBackoff에서 점진적으로 maxBackoff 재시도 함.) factor: 2Gateway Retry Filter를 사용할 때 주의할 점
-
Route되는 서비스가 요청 처리 불가한 상태인 SERVICE_UNAVAILABLE만 Retry되도록 설정한다.
-
Body(본문)가 포함되는 POST, PUT 등의 요청은 Retry Filter가 내부적으로 메모리에 캐시하기 때문에 부하가 발생할 수 있다.
(참고: Spring Cloud Gateway Retry Filter, Spring Cloud Gateway가 요청을 캐시하는 이유)
Spring Cloud OpenFeign을 사용한다면 feign의 retryer를 설정하거나 resilience4j.retry을 설정하여 재시도 되도록 할 수 있다.
-
**Retry Filter 메모리에 캐시 최소화 **
Gateway의 Retry Filter만 적용하더라도 큰 문제 없이 동작할 것이다. 그러나 많은 요청이 들어오고 있는 상황에서 긴급하게 업데이트 배포해야 되는 상황이라면 Retry로 인한 Gateway의 부하가 서비스 장애로 이어질 가능성도 있다.
서버가 shutdown되는 경우는 어쩔 수 없지만 배포 시에는 아래와 같은 방법으로 Retry가 발생하지 않도록 할 수 있다.
배포할 서비스를 shutdown하지 않고 수동으로 Eureka에 등록 해제한다.
- 다른 서비스에서 Eureka의 서비스 목록을 fetch할 동안 UP상태에서 응답을 처리하도록 한다.
registry-fetch-interval-seconds 만큼 대기한다.
- registry-fetch-interval-seconds 이후에는 다른 서비스가 서비스 목록을 fetch할 것이므로 더이상 현재 서버로 요청이 오지 않는다.
신규 버전의 jar파일을 적용하고 restart 한다.
위와 같은 방법을 적용하기 전에 두 가지 설정을 해야 한다.
1. Spring Cloud LoadBalancer 캐시 비활성화
Spring Cloud LoadBalancer 공식 문서에서 다음과 같은 글을 확인할 수 있었다.
3.4.2. Default LoadBalancer Cache Implementation
If you do not have Caffeine in the classpath, the
DefaultLoadBalancerCache, which comes automatically withspring-cloud-starter-loadbalancer, will be used. See the LoadBalancerCacheConfiguration section for information on how to configure it.3.4.3. LoadBalancer Cache Configuration
….
You can also altogether disable loadBalancer caching by setting the value of
spring.cloud.loadbalancer.cache.enabledtofalse.Warning
Although the basic, non-cached, implementation is useful for prototyping and testing, it’s much less efficient than the cached versions, so we recommend always using the cached version in production. If the caching is already done by the
DiscoveryClientimplementation, for exampleEurekaDiscoveryClient, the load-balancer caching should be disabled to prevent double caching.
Spring Cloud LoadBalancer는 기본적으로 DefaultLoadBalancerCache가 활성화되어 있다. 만약 Eurkea와 같은 Discovery Client를 사용하여 캐싱을 수행하는 경우 이중 캐싱을 방지하기 위해 로드 밸런서 캐싱을 비활성화해야 한다고 한다.
Spring Cloud Gateway 설정에 다음과 같이 로드 밸랜서 캐싱을 비활성화 한다.
spring:
cloud:
loadbalancer:
cache:
enabled: false
만약 이 설정을 하지 않으면 Spring Cloud Gateway가 eureka로부터 서비스 목록을 갱신하였음에도 불구하고 LoadBalancer의 캐시를 사용하여 registry-fetch-interval-seconds 이후에도 서비스로 요청을 보내어 Retry가 발생할 수 있다.
2. Eureka 응답 캐시 설정
Eureka에 등록된 Spring Cloud Gateway 및 서비스는 registry-fetch-interval-seconds 마다 Eureka에 등록된 서비스 정보를 가져오도록 되어 있다. 그런데 Eureka에서 응답하는 서비스 목록은 Eureka 내부에 캐시된 정보이기 때문에 Eureka Client에서 가져간 정보가 최신 정보가 아닐 수도 있는 것이다.
Eureka Server의 응답 캐시 주기는 response-cache-update-interval-ms 속성으로 지정할 수 있으며 기본 값은 30초이다. 이 값을 낮게 설정하여 서비스 캐시를 최신으로 유지하도록 한다.
eureka:
server:
response-cache-update-interval-ms: 1000
배포 방법 테스트
-
테스트할 spring boot 서비스(Eureka client)에 다음과은 Shutdown EndPoint를 생성한다.
@RestController @RequiredArgsConstructor public class EurekaActuatorController { private final EurekaClient eurekaClient; private final EurekaInstanceConfig eurekaInstanceConfig; @PostMapping("/actuator/eureka-shutdown") public void eurekaShutdown() throws InterruptedException { eurekaClient.shutdown(); int registryFetchIntervalSeconds = this.eurekaClient.getEurekaClientConfig().getRegistryFetchIntervalSeconds(); int registryFetchIntervalMilliseconds = registryFetchIntervalSeconds * 1000; Thread.sleep(registryFetchIntervalMilliseconds); } } -
테스트할 서비스 두 개를 시작한다.
두 개의 서비스는 Eureka 등록 후 Spring Cloud Gateway에 fetch된다.
-
Postman으로 테스트할 엔드포인트를 일정시간 동안 반복 실행한다.
-
하나의 서비스에 eureka-shutdown를 요청한다.
POST http://localhost:19093/actuator/eureka-shutdown -
30초(registry-fetch-interval-seconds)를 기다렸다가 서비스를 shutdown 한다.
-
테스트를 확인 해본다.

롤링 무중단 배포 정리
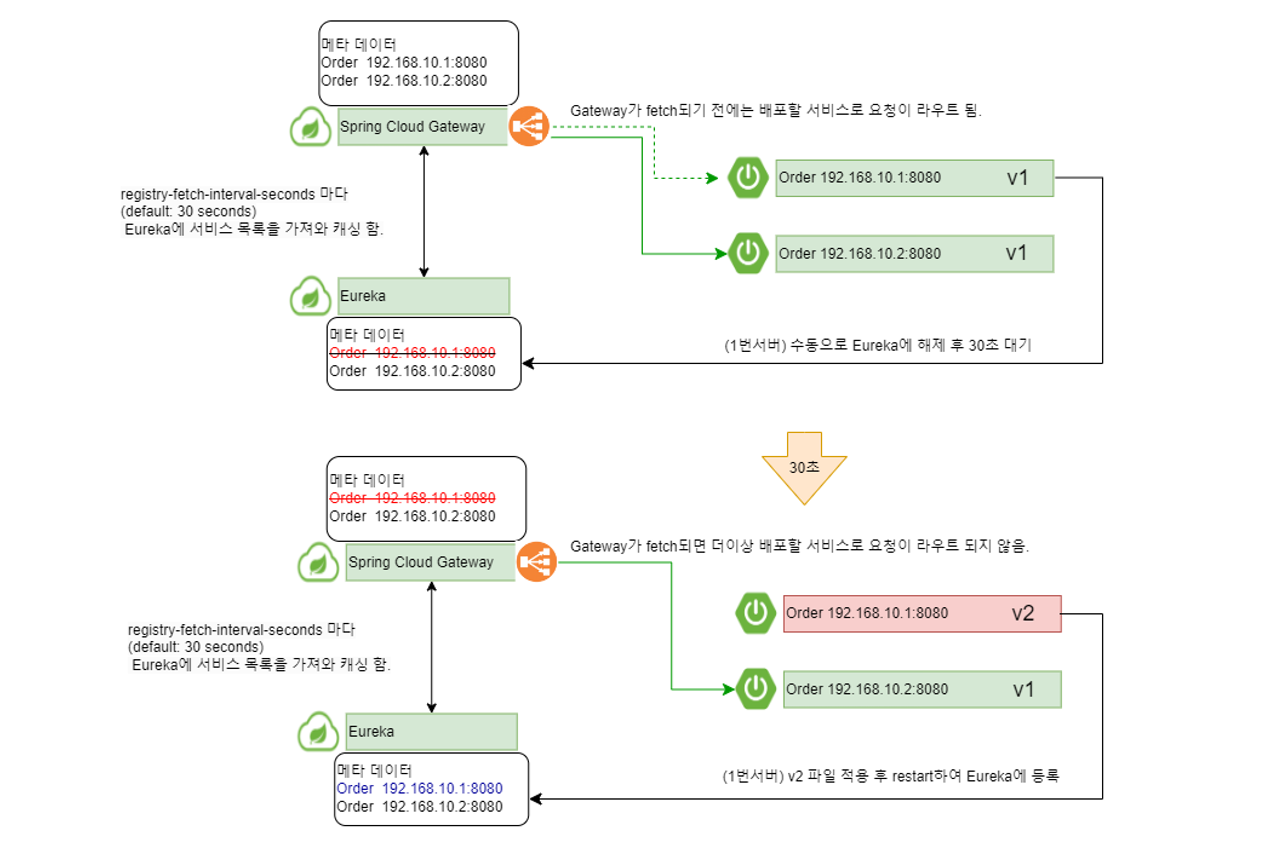
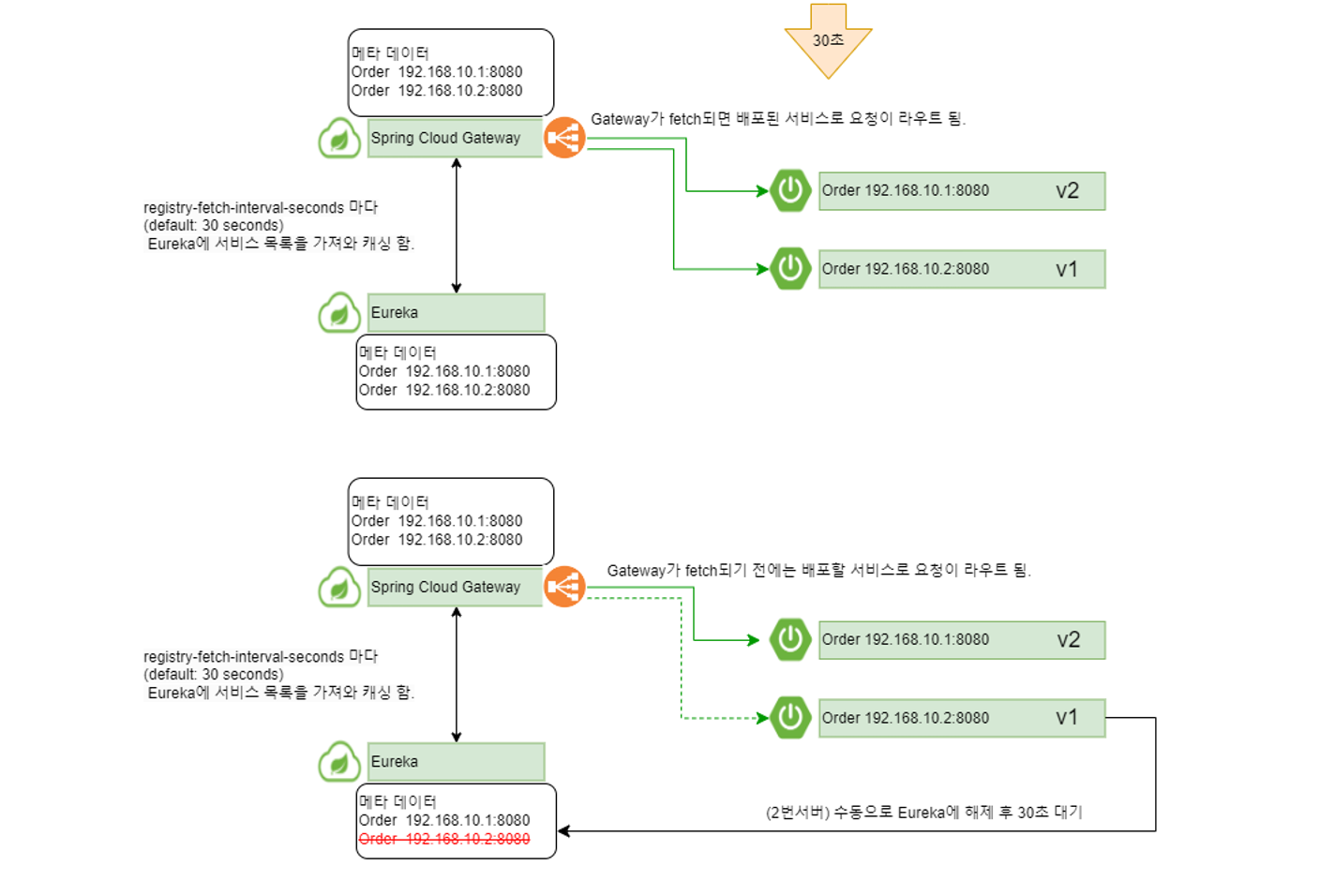
배포 과정
- Github branch에 push하면 webhook으로 jenkins가 실행된다.
- jenkins에서 빌드 후 jar파일과 배포 스크립트를 서버로 전송한다.
- jenkins 명령 커맨드로 배포 스크립트를 실행한다.
배포 스크립트
-
배포할 서비스에 POST http://localhost:{서비스포트}/actuator/eureka-shutdown 엔드포인트를 호출하고 응답이 올때까지 기다린다.
-
기존 버전 파일을 백업한다.
-
신규 버전 파일을 복사하고 서비스를 재시작한다.
-
sleep 10 (서비스 로드 시간 10초)
-
서비스에 GET http://localhost:{서비스포트}/actuator/health 요청을 보내어 200 응답이 올때까지 반복하여 대기한다. (최대 60회 시도 )
-
health check가 정상이면 exit 0 종료한다.
-
만약 운영중인 서비스 인스턴스가 총 2대라면 배포 후 다음 인스턴스를 배포하기 전에 sleep 30 하여
현재 인스턴스가 다른 인스턴스에 eureka fetch되는 시간을 기다려주고 종료해야 한다.
health check가 실패이면 백업파일로 복구한다음 서비스를 재시작하고 exit 1 종료한다.
-
배포 스크립트가 정상 완료될 때만 다음 서버 인스턴스에 롤링 배포를 시작한다.
댓글남기기